Например, компания может запустить механизм анализа текста, который обрабатывает твиты о своей компании с упоминанием названия компании, местоположения, обрабатывает и анализирует эмоции, связанные с этим твитом. Правильные действия можно предпринять быстрее, если бизнес узнает о росте негативных твитов в определенном месте, чтобы спастись от промаха или чего-то еще. Другой распространенный пример будет для YouTube. Администраторы и модераторы Youtube узнают об эффекте видео в зависимости от типа комментариев, сделанных к видео или сообщениям видеочата. Это поможет им намного быстрее находить неприемлемый контент на веб-сайте, потому что теперь они устранили ручную работу и использовали автоматизированных роботов для интеллектуального анализа текста.
В этом уроке мы изучим некоторые концепции, связанные с анализом текста с помощью библиотеки NLTK в Python. Некоторые из этих концепций включают:
- Токенизация, как разбить кусок текста на слова, предложения
- Избегайте стоп-слов на основе английского языка
- Выполнение стемминга и лемматизации фрагмента текста
- Определение токенов для анализа
НЛП будет основной областью внимания в этом уроке, поскольку оно применимо к огромным сценариям реальной жизни, где оно может решить большие и важные проблемы. Если вы думаете, что это звучит сложно, это так, но концепции одинаково легко понять, если вы попробуете примеры рядом. Давайте перейдем к установке NLTK на вашем компьютере, чтобы начать с ним работать.
Установка NLTK
Обратите внимание, перед тем как начать, вы можете использовать виртуальную среду для этого урока, что можно сделать с помощью следующей команды:
Python -m virtualenv nltkисточник nltk / bin / активировать
После того, как виртуальная среда станет активной, вы можете установить библиотеку NLTK в виртуальной среде, чтобы можно было выполнять следующие примеры:
pip install nltkВ этом уроке мы будем использовать Anaconda и Jupyter. Если вы хотите установить его на свой компьютер, посмотрите урок, который описывает «Как установить Anaconda Python на Ubuntu 18».04 LTS »и поделитесь своим мнением, если у вас возникнут проблемы. Чтобы установить NLTK с Anaconda, используйте следующую команду в терминале от Anaconda:
conda install -c anaconda nltkМы видим что-то подобное, когда выполняем указанную выше команду:
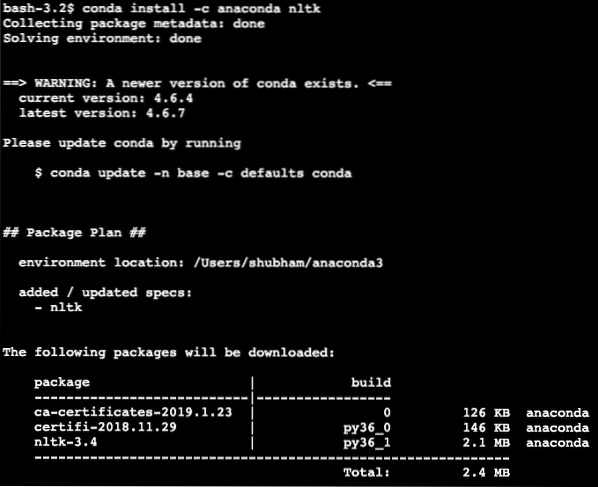
После того, как все необходимые пакеты установлены и выполнены, мы можем начать использовать библиотеку NLTK с помощью следующего оператора импорта:
импортировать nltkДавайте начнем с основных примеров NLTK, теперь, когда у нас установлены необходимые пакеты.
Токенизация
Мы начнем с токенизации, которая является первым шагом в выполнении анализа текста. Токеном может быть любая меньшая часть текста, которую можно проанализировать. Существует два типа токенизации, которые можно выполнить с помощью NLTK:
- Токенизация предложения
- Токенизация слов
Вы можете догадаться, что происходит при каждой токенизации, поэтому давайте погрузимся в примеры кода.
Токенизация предложения
Как видно из названия, токенизаторы предложений разбивают фрагмент текста на предложения. Давайте попробуем простой фрагмент кода для того же самого, где мы используем текст, взятый из учебника Apache Kafka. Осуществим необходимый импорт
импортировать nltkиз НЛТК.tokenize import sent_tokenize
Обратите внимание, что вы можете столкнуться с ошибкой из-за отсутствия зависимости для nltk, называемого пункт. Добавьте следующую строку сразу после импорта в программу, чтобы избежать каких-либо предупреждений:
nltk.скачать ('пункт')Для меня это дало следующий результат:
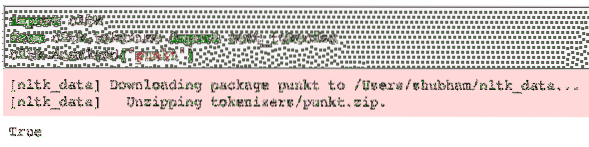
Затем мы используем импортированный токенизатор предложений:
text = "" "Тема в Kafka - это то, куда отправляется сообщение. Потребительприложения, которые заинтересованы в этой теме, помещают сообщение внутри этого
тема и может делать что угодно с этими данными. До определенного времени любое количество
потребительские приложения могут получать это сообщение любое количество раз."" "
предложения = sent_tokenize (текст)
печать (предложения)
Мы видим что-то подобное, когда выполняем приведенный выше скрипт:

Как и ожидалось, текст был правильно организован в предложения.
Токенизация слов
Как видно из названия, токенизаторы Word разбивают фрагмент текста на слова. Давайте попробуем простой фрагмент кода для того же самого с тем же текстом, что и в предыдущем примере:
из НЛТК.токенизировать импорт word_tokenizeслова = word_tokenize (текст)
печать (слова)
Мы видим что-то подобное, когда выполняем приведенный выше скрипт:

Как и ожидалось, текст был правильно организован по словам.
Распределение частоты
Теперь, когда мы разорвали текст, мы также можем вычислить частоту каждого слова в тексте, который мы использовали. Это очень просто сделать с NLTK, вот фрагмент кода, который мы используем:
из НЛТК.вероятность импорта FreqDistраспределение = FreqDist (слова)
печать (распространение)
Мы видим что-то подобное, когда выполняем приведенный выше скрипт:

Затем мы можем найти наиболее распространенные слова в тексте с помощью простой функции, которая принимает количество отображаемых слов:
# Самые распространенные словараспределение.most_common (2)
Мы видим что-то подобное, когда выполняем приведенный выше скрипт:

Наконец, мы можем составить график частотного распределения, чтобы убрать слова и их количество в данном тексте и четко понять распределение слов:

Stopwords
Точно так же, как когда мы разговариваем с другим человеком по телефону, во время разговора появляется некоторый шум, который является нежелательной информацией. Таким же образом текст из реального мира также содержит шум, который называется Stopwords. Стоп-слова могут отличаться от языка к языку, но их легко идентифицировать. Некоторые из стоп-слов на английском языке могут быть - is, are, a, the, an и т. Д.
Мы можем посмотреть слова, которые NLTK считает стоп-словами для английского языка, с помощью следующего фрагмента кода:
из НЛТК.корпус импортных игнорируемых словnltk.скачать ('игнорируемые слова')
language = "english"
stop_words = set (стоп-слова.слова (язык))
печать (стоп-слова)
Поскольку, конечно, набор стоп-слов может быть большим, он хранится как отдельный набор данных, который можно загрузить с помощью NLTK, как мы показали выше. Мы видим что-то подобное, когда выполняем приведенный выше скрипт:
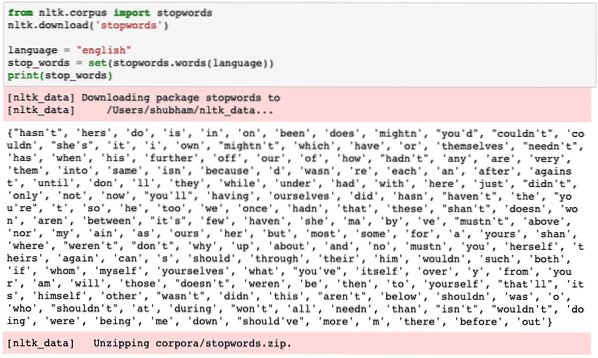
Эти стоп-слова следует удалить из текста, если вы хотите выполнить точный анализ текста для предоставленного фрагмента текста. Давайте удалим стоп-слова из наших текстовых токенов:
filter_words = []словом в словах:
если слово не в stop_words:
filter_words.добавить (слово)
filter_words
Мы видим что-то подобное, когда выполняем приведенный выше скрипт:

Слово Stemming
Основа слова - это основа этого слова. Например:
Мы выполним выделение отфильтрованных слов, из которых мы удалили стоп-слова в последнем разделе. Давайте напишем простой фрагмент кода, в котором мы используем стеммер NLTK для выполнения операции:
из НЛТК.стволовый импорт PorterStemmerps = PorterStemmer ()
stemmed_words = []
для слова в filter_words:
stemmed_words.добавить (пс.ствол (слово))
print ("Выделенное предложение:", stemmed_words)
Мы видим что-то подобное, когда выполняем приведенный выше скрипт:

POS-теги
Следующим шагом в текстовом анализе после выделения корней является определение и группировка каждого слова с точки зрения их значения, т.е.е. если каждое слово является существительным или глаголом или чем-то еще. Это называется частью речевого тегирования. Теперь выполним POS-теги:
токены = nltk.word_tokenize (предложения [0])печать (токены)
Мы видим что-то подобное, когда выполняем приведенный выше скрипт:

Теперь мы можем выполнить тегирование, для чего нам нужно будет загрузить другой набор данных, чтобы определить правильные теги:
nltk.скачать ('averaged_perceptron_tagger')nltk.pos_tag (токены)
Вот результат разметки:
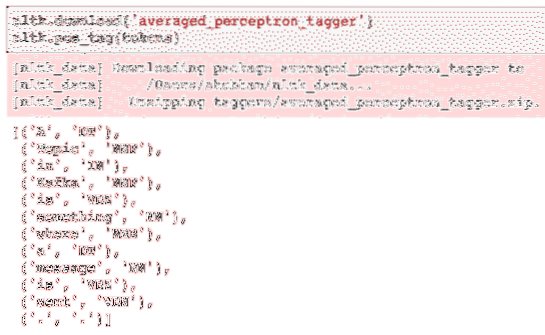
Теперь, когда мы наконец определили помеченные слова, это набор данных, на котором мы можем выполнить анализ настроений, чтобы определить эмоции, стоящие за предложением.
Заключение
В этом уроке мы рассмотрели превосходный пакет естественного языка, NLTK, который позволяет нам работать с неструктурированными текстовыми данными, чтобы идентифицировать любые стоп-слова и выполнять более глубокий анализ, подготавливая точный набор данных для анализа текста с помощью таких библиотек, как sklearn.
Найдите весь исходный код, использованный в этом уроке, на Github. Поделитесь своими отзывами об уроке в Twitter с @sbmaggarwal и @LinuxHint.


