В этом уроке мы собираемся сделать это. Мы узнаем, как могут быть извлечены значения различных HTML-тегов, а также переопределим функциональность этого модуля по умолчанию, чтобы добавить некоторую собственную логику. Мы сделаем это с помощью HTMLParser класс в Python в html.парсер модуль. Посмотрим код в действии.
Глядя на класс HTMLParser
Чтобы проанализировать HTML-текст в Python, мы можем использовать HTMLParser класс в html.парсер модуль. Давайте посмотрим на определение класса для HTMLParser класс:
класс html.парсер.HTMLParser (*, convert_charrefs = True)В convert_charrefs поле, если установлено значение True, все ссылки на символы будут преобразованы в их эквиваленты Unicode. Только сценарий / стиль элементы не конвертируются. Теперь мы попытаемся понять каждую функцию для этого класса, чтобы лучше понять, что делает каждая функция.
- handle_startendtag Это первая функция, которая запускается при передаче строки HTML экземпляру класса. Как только текст достигает этого места, управление передается другим функциям в классе, который сужается до других тегов в строке. Это также ясно из определения этой функции: def handle_startendtag (self, tag, attrs):
себя.handle_starttag (тег, attrs)
себя.handle_endtag (тег) - handle_starttag: Этот метод управляет начальным тегом получаемых данных. Его определение показано ниже: def handle_starttag (self, tag, attrs):
проходить - handle_endtag: Этот метод управляет конечным тегом для данных, которые он получает: def handle_endtag (self, tag):
проходить - handle_charref: Этот метод управляет ссылками на символы в данных, которые он получает. Его определение показано ниже: def handle_charref (self, name):
проходить - handle_entityref: Эта функция обрабатывает ссылки на сущности в переданном ей HTML: def handle_entityref (self, name):
проходить - handle_data: Это функция, в которой выполняется реальная работа по извлечению значений из тегов HTML и передаче данных, связанных с каждым тегом. Его определение показано ниже: def handle_data (self, data):
проходить - handle_comment: Используя эту функцию, мы также можем получить комментарии, прикрепленные к источнику HTML: def handle_comment (self, data):
проходить - handle_pi: Поскольку HTML также может иметь инструкции по обработке, это функция, определение которой показано ниже: def handle_pi (self, data):
проходить - handle_decl: Этот метод обрабатывает объявления в HTML, его определение предоставляется как: def handle_decl (self, decl):
проходить
Создание подкласса класса HTMLParser
В этом разделе мы создадим подкласс класса HTMLParser и рассмотрим некоторые функции, вызываемые при передаче данных HTML в экземпляр класса. Напишем простой скрипт, который все это сделает:
из HTML.парсер импорт HTMLParserкласс LinuxHTMLParser (HTMLParser):
def handle_starttag (self, tag, attrs):
print ("Обнаружен начальный тег:", тег)
def handle_endtag (сам, тег):
print ("Обнаружен конечный тег:", тег)
def handle_data (self, data):
print ("Данные найдены:", данные)
parser = LinuxHTMLParser ()
парсер.кормить("
'
Модуль синтаксического анализа Python HTML
')
Вот что мы получаем с помощью этой команды:
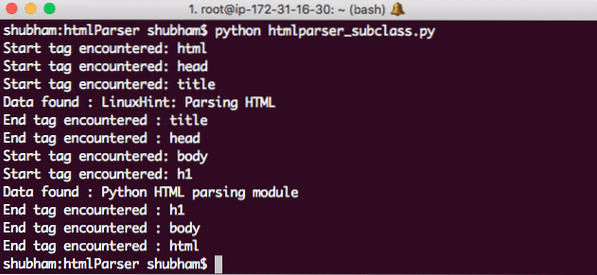
Подкласс Python HTMLParser
HTMLParser функции
В этом разделе мы будем работать с различными функциями класса HTMLParser и рассмотрим функциональность каждой из них:
из HTML.парсер импорт HTMLParserиз HTML.сущности импортируют name2codepoint
класс LinuxHint_Parse (HTMLParser):
def handle_starttag (self, tag, attrs):
print ("Начальный тег:", тег)
для attr в attrs:
print ("attr:", attr)
def handle_endtag (сам, тег):
print ("Конечный тег:", тег)
def handle_data (self, data):
print ("Данные:", данные)
def handle_comment (self, data):
print ("Комментарий:", данные)
def handle_entityref (я, имя):
c = chr (name2codepoint [имя])
print ("Именованный энт:", c)
def handle_charref (я, имя):
если имя.начинается с ('x'):
c = chr (int (имя [1:], 16))
еще:
c = chr (int (имя))
print ("Число:", c)
def handle_decl (себя, данные):
print ("Decl:", данные)
парсер = LinuxHint_Parse ()
С помощью различных вызовов давайте скармливаем этому экземпляру отдельные данные HTML и посмотрим, какой вывод генерируют эти вызовы. Начнем с простого DOCTYPE нить:
парсер.кормить(''"http: // www.w3.org / TR / html4 / strict.dtd "> ')Вот что мы получаем с этим вызовом:
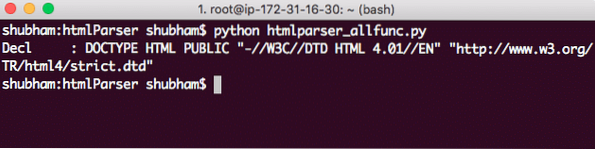
DOCTYPE String
Давайте теперь попробуем тег изображения и посмотрим, какие данные он извлекает:
парсер.кормить(' ')
') Вот что мы получаем с этим вызовом:

HTMLParser тег изображения
Затем давайте попробуем, как тег скрипта ведет себя с функциями Python:
парсер.кормить('')парсер.кормить('')
парсер.feed ('# питон цвет: зеленый')
Вот что мы получаем с этим вызовом:

Тег скрипта в htmlparser
Наконец, мы также передаем комментарии в раздел HTMLParser:
парсер.кормить('''')
Вот что мы получаем с этим вызовом:

Анализ комментариев
Заключение
В этом уроке мы рассмотрели, как мы можем анализировать HTML, используя собственный класс Python HTMLParser без какой-либо другой библиотеки. Мы можем легко изменить код, чтобы изменить источник данных HTML на HTTP-клиент.
Прочтите больше сообщений на основе Python здесь.


