Использование метода format ()
формат() Метод является важным методом Python для создания форматированного вывода. Он имеет множество применений и может применяться как к строковым, так и к числовым данным для генерации форматированного вывода. Как этот метод можно использовать для форматирования строковых данных на основе индекса, показано в следующем примере.
Синтаксис:
.формат (значение)Строка и позиция заполнителя определяются внутри фигурных скобок (). Он возвращает отформатированную строку на основе строки и значений, переданных в позиции заполнителя.
Пример:
Четыре типа форматирования показаны в следующем скрипте. В первом выводе используется значение индекса 0. На втором выходе позиция не назначена. На третьем выходе назначаются две последовательные позиции. В четвертом выводе определены три неупорядоченные позиции.
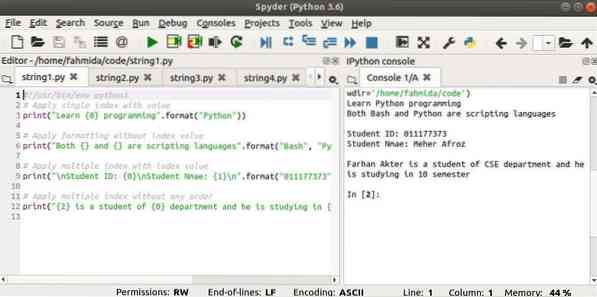
#!/ usr / bin / env python3# Применить единый индекс со значением
print ("Изучите 0 программирование".формат ("Python"))
# Применить форматирование без значения индекса
print ("И , и являются языками сценариев".format ("Bash", "Python"))
# Применяем множественный индекс со значением индекса
print ("\ nStudent ID: 0 \ nStudent Nmae: 1 \ n".формат («011177373», «Мехер Афроз»))
# Применяем множественный индекс без какого-либо порядка
print ("2 учится на отделении 0 и учится в семестре 1".формат ("СПП",
«10», «Фархан Актер»))
Выход:
Использование метода split ()
Этот метод используется для разделения любых строковых данных на основе любого конкретного разделителя или разделителя. Может принимать два аргумента, и оба необязательны.
Синтаксис:
split ([разделитель, [maxsplit]])Если этот метод используется без аргументов, то по умолчанию в качестве разделителя будет использоваться пробел. В качестве разделителя можно использовать любой символ или список символов. Второй необязательный аргумент используется для определения предела разделения строки. Он возвращает список строк.
Пример:
Следующий сценарий показывает использование раскол () метод без аргументов, с одним аргументом и с двумя аргументами. Космос используется для разделения строки, когда аргумент не используется. Далее двоеточие(:) используется в качестве аргумента-разделителя. В запятая (,) используется как разделитель, а 2 используется как номер разделения в последнем операторе разделения.
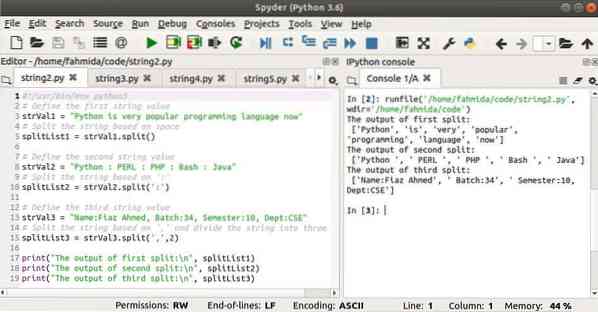
#!/ usr / bin / env python3# Определить первое строковое значение
strVal1 = "Python сейчас очень популярный язык программирования"
# Разделить строку по пробелу
splitList1 = strVal1.расколоть()
# Определить второе строковое значение
strVal2 = "Python: PERL: PHP: Bash: Java"
# Разделить строку на основе ':'
splitList2 = strVal2.расколоть(':')
# Определить третье строковое значение
strVal3 = "Имя: Фиаз Ахмед, партия: 34, семестр: 10, отдел: CSE"
# Разделить строку на основе ',' и разделить строку на три части
splitList3 = strVal3.сплит (',', 2)
print ("Результат первого разделения: \ n", splitList1)
print ("Результат второго разделения: \ n", splitList2)
print ("Результат третьего разделения: \ n", splitList3)
Выход:
Использование метода find ()
найти() используется для поиска позиции определенной строки в основной строке и возврата позиции, если строка существует в основной строке.
Синтаксис:
find (searchText, [начальная_позиция, [конечная_позиция]])Этот метод может принимать три аргумента, где первый аргумент является обязательным, а два других аргумента - необязательными. Первый аргумент содержит строковое значение, в котором будет выполняться поиск, второй аргумент определяет начальную позицию поиска, а третий аргумент определяет конечную позицию поиска. Возвращает позицию searchText если он существует в основной строке, в противном случае возвращает -1.
Пример:
Использование найти() метод с одним аргументом, двумя аргументами и третьим аргументом показан в следующем скрипте. Первый вывод будет -1, потому что поисковый текст - 'питон'и переменная, ул содержит строку 'Python'. Второй вывод вернет правильную позицию, потому что слово, 'программа'существует в ул после должности10. Третий вывод вернет правильную позицию, потому что слово, 'зарабатывать'существует в пределах от 0 до 5 позиции ул.
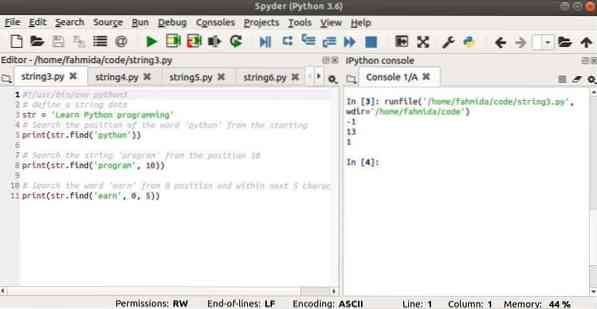
#!/ usr / bin / env python3# определяем строковые данные
str = 'Изучите программирование на Python'
# Поиск позиции слова 'python' с начала
печать (str.найти ('питон'))
# Искать строку 'program' с позиции 10
печать (str.find ('программа', 10))
# Искать слово "зарабатывать" с позиции 0 и в пределах следующих 5 символов
печать (str.find ('заработать', 0, 5))
Выход:
Использование метода replace ()
заменять() используется для замены любой конкретной части строковых данных другой строкой, если найдено совпадение. Может принимать три аргумента. Два аргумента являются обязательными, а один - необязательным.
Синтаксис:
нить.replace (search_string, replace_string [, counter])Первый аргумент принимает строку поиска, которую вы хотите заменить, а второй аргумент принимает строку замены. Третий необязательный аргумент устанавливает предел замены строки.
Пример:
В следующем сценарии первая замена используется для замены слова 'PHPк слову,Ява'в содержании ул. Искомое слово существует в ул, так что слово, 'PHP' будет заменено словом "Ява'. Третий аргумент метода замены используется в следующем методе замены, и он заменит только первое совпадение искомого слова.
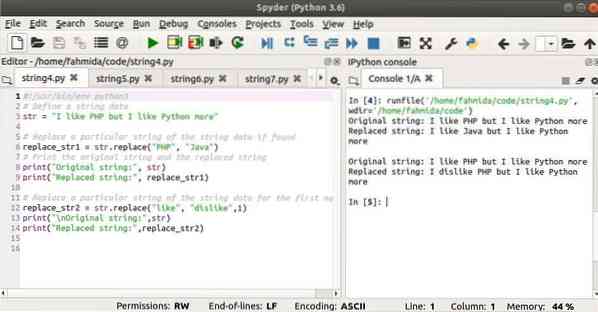
#!/ usr / bin / env python3# Определить строковые данные
str = "Мне нравится PHP, но мне больше нравится Python"
# Заменить конкретную строку строковых данных, если она найдена
replace_str1 = str.replace ("PHP", "Java")
# Распечатать исходную строку и замененную строку
print ("Исходная строка:", str)
print ("Замененная строка:", replace_str1)
# Заменить конкретную строку строковых данных на первое совпадение
replace_str2 = str.replace («нравится», «не нравится», 1)
print ("\ nОригинальная строка:", str)
print ("Замененная строка:", replace_str2)
Выход:
Использование метода join ()
присоединиться() используется для создания новой строки путем объединения другой строки со строкой, списком строк или кортежем данных строк.
Синтаксис:
разделитель.присоединиться (повторяемый)У него есть только один аргумент, который может быть строкой, списком или кортежем, а разделитель содержит строковое значение, которое будет использоваться для конкатенации.
Пример:
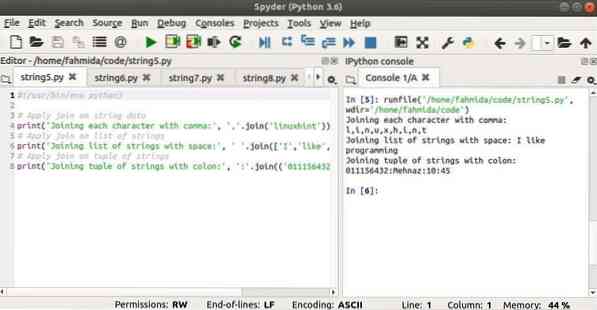
В следующем сценарии показано использование метода join () для строки, списка строки и кортежа строк. ',' используется как разделитель для строки, пробел используется как разделитель для списка, а ':' используется как разделитель для кортежа.
#!/ usr / bin / env python3# Применить соединение к строковым данным
print ('Соединение каждого символа запятой:', ','.присоединиться ('linuxhint'))
# Применить соединение к списку строк
print ('Объединение списка строк с пробелом:', ".join (['Я', 'нравится', 'программирование']))
# Применить соединение к кортежу строк
print ('Объединение кортежа строк с двоеточием:', ':'.присоединиться (('011156432', 'Mehnaz', '10', '45')))
Выход:
Использование метода strip ()
полоска() используется для удаления пробелов с обеих сторон строки. Есть два связанных метода удаления пробелов. lstrip () метод удаления белого пространства с левой стороны и rstrip () метод удаления пробела с правой стороны строки. Этот метод не принимает никаких аргументов.
Синтаксис:
нить.полоска()Пример:
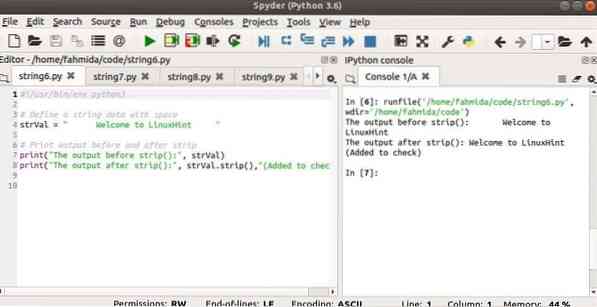
Следующий сценарий показывает использование полоска() метод для строкового значения, содержащего много пробелов до и после строки. Дополнительный текст добавляется к выходным данным метода strip (), чтобы показать, как этот метод работает.
#!/ usr / bin / env python3# Определяем строковые данные с пробелом
strVal = "Добро пожаловать в LinuxHint"
# Вывод на печать до и после полосы
print ("Вывод перед полосой ():", strVal)
print ("Вывод после strip ():", strVal.strip (), "(Добавлено для проверки)")
Выход:
Использование метода capitalize ()
капитализировать () используется для преобразования первого символа строковых данных с заглавной буквы и перевода остальных символов в нижний регистр.
Синтаксис:
нить.капитализировать ()Этот метод не принимает никаких аргументов. Он возвращает строку после преобразования первого символа в верхний регистр, а оставшиеся символы в нижний регистр.
Пример:
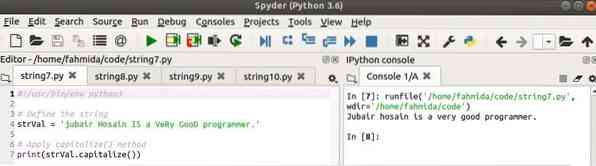
В следующем скрипте строковая переменная определяется сочетанием символов верхнего и нижнего регистра. В капитализировать () преобразует первый символ строки в заглавную букву, а остальные символы в маленькие буквы.
#!/ usr / bin / env python3# Определить строку
strVal = 'jubair Hosain ЯВЛЯЕТСЯ программистом VeRy GooD.'
# Применить метод capitalize ()
печать (strVal.капитализировать ())
Выход:
Использование метода count ()
считать() используется для подсчета того, сколько раз конкретная строка появляется в тексте.
Синтаксис:
нить.счетчик (текст_поиска [, начало [, конец]])Этот метод имеет три аргумента. Первый аргумент является обязательным, а два других аргумента - необязательными. Первый аргумент содержит значение, которое требуется для поиска в тексте. Второй аргумент содержит начальную позицию поиска, а третий аргумент содержит конечную позицию поиска.
Пример:
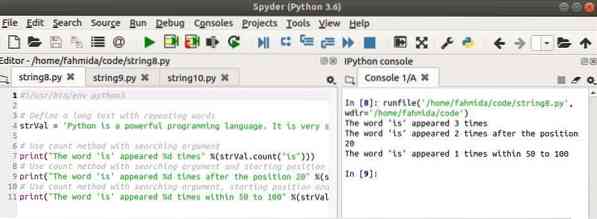
Следующий сценарий показывает три различных использования считать() метод. Первое считать() метод будет искать слово, 'является'в переменной, strVal. Второй считать() метод ищет то же слово с позиции 20. Третий считать() метод ищет то же слово в позиции 50 к 100.
#!/ usr / bin / env python3# Определите длинный текст с повторяющимися словами
strVal = 'Python - мощный язык программирования. Очень просто использовать.
Это отличный язык для изучения программирования для начинающих.'
# Использовать метод count с аргументом поиска
print ("Слово 'is' появилось% d раз"% (strVal.count ("есть")))
# Использовать метод count с аргументом поиска и начальной позицией
print ("Слово 'is' появилось% d раз после позиции 20"% (strVal.count ("есть", 20)))
# Использовать метод count с аргументом поиска, начальной и конечной позицией
print ("Слово 'is' появлялось% d раз в диапазоне от 50 до 100"% (strVal.count ("есть", 50, 100)))
Выход:
Использование метода len ()
len () используется для подсчета общего количества символов в строке.
Синтаксис:
len (строка)Этот метод принимает любое строковое значение в качестве аргумента и возвращает общее количество символов этой строки.
Пример:
В следующем скрипте строковая переменная с именем strVal объявлен со строковыми данными. Затем будет напечатано значение переменной и общее количество символов, которые существуют в переменной.
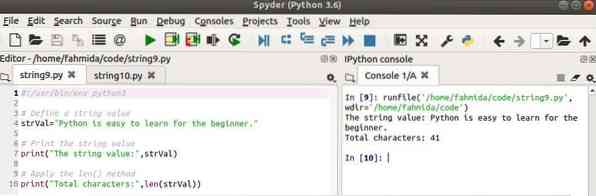
#!/ usr / bin / env python3# Определить строковое значение
strVal = "Python легко освоить для новичка."
# Распечатать строковое значение
print ("Строковое значение:", strVal)
# Применяем метод len ()
print ("Всего символов:", len (strVal))
Выход:
Использование метода index ()
индекс() метод работает как найти() метод, но есть одно различие между этими методами. Оба метода возвращают позицию искомого текста, если строка существует в основной строке. Если искомого текста нет в основной строке, тогда найти() метод возвращает -1, но индекс() метод генерирует ValueError.
Синтаксис:
нить.индекс (текст_поиска [, начало [, конец]])Этот метод имеет три аргумента. Первый аргумент является обязательным и содержит поисковый текст. Два других аргумента являются необязательными и содержат начальную и конечную позицию поиска.
Пример:
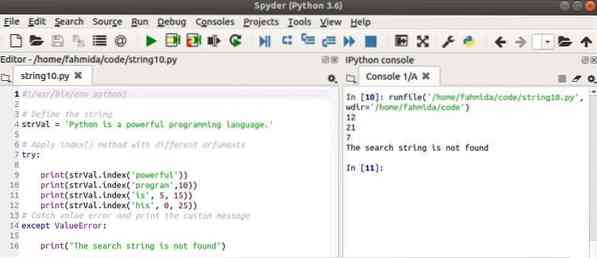
индекс() метод используется 4 раза в следующем скрипте. попробовать-исключитьБлок t используется здесь для обработки ValueError. Индекс() используется с одним аргументом в первом выводе, который будет искать слово, 'мощный'в переменной, strVal. Следующий, индекс () метод будет искать слово, 'программа' с позиции 10 что существует в strVal. Далее индекс() метод будет искать слово, 'является' в позиции 5 к 15 что существует в strVal. Последний метод index () будет искать слово, 'его' в 0 к 25 этого не существует в strVal.
#!/ usr / bin / env python3# Определить строку
strVal = 'Python - мощный язык программирования.'
# Применяем метод index () с разными аргументами
пытаться:
печать (strVal.index ('мощный'))
печать (strVal.index ('программа', 10))
печать (strVal.index ('есть', 5, 15))
печать (strVal.index ('его', 0, 25))
# Поймать ошибку значения и распечатать собственное сообщение
кроме ValueError:
print («Строка поиска не найдена»)
Выход:
Заключение:
Наиболее часто используемые встроенные методы строки Python описаны в этой статье с использованием очень простых примеров, чтобы понять использование этих методов и помочь новому Python использовать.


