20 примеров awk
В операционной системе Linux существует множество служебных инструментов для поиска и создания отчета из текстовых данных или файлов. Пользователь может легко выполнять множество типов задач поиска, замены и создания отчетов с помощью команд awk, grep и sed. awk - это не просто команда. Это язык сценариев, который можно использовать как из терминала, так и из файла awk. Он поддерживает переменную, условный оператор, массив, циклы и т. Д. как и другие языки сценариев. Он может читать содержимое любого файла построчно и разделять поля или столбцы на основе определенного разделителя. Он также поддерживает регулярное выражение для поиска определенной строки в текстовом содержимом или файле и выполняет действия, если найдено какое-либо совпадение. В этом руководстве показано, как использовать команду и скрипт awk на 20 полезных примерах.
Содержание:
- awk с printf
- awk разделить на пустое пространство
- awk, чтобы изменить разделитель
- awk с данными, разделенными табуляцией
- awk с данными CSV
- регулярное выражение awk
- регулярное выражение без учета регистра в awk
- awk с переменной nf (количество полей)
- функция awk gensub ()
- awk с функцией rand ()
- пользовательская функция awk
- awk если
- переменные awk
- массивы awk
- цикл awk
- awk для печати первого столбца
- awk для печати последнего столбца
- awk с grep
- awk с файлом сценария bash
- awk с sed
Использование awk с printf
printf () функция используется для форматирования любого вывода на большинстве языков программирования. Эту функцию можно использовать с awk команда для генерации различных типов форматированных выходных данных. Команда awk в основном используется для любого текстового файла. Создайте текстовый файл с именем работник.текст с приведенным ниже содержанием, где поля разделены табуляцией ('\ t').
работник.текст
1001 Джон сена 400001002 Джафар Икбал 60000
1003 Мехер Нигяр 30000
1004 Джонни Ливер 70000
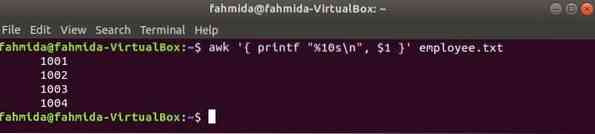
Следующая команда awk будет читать данные из работник.текст файл построчно и распечатать первое поле после форматирования. Здесь, "% 10s \ n”Означает, что вывод будет состоять из 10 символов. Если значение вывода меньше 10 символов, то перед значением будут добавлены пробелы.
Сотрудник $ awk 'printf "% 10s \ n", $ 1'.текстВыход:
Перейти к содержанию
awk разделить на пустое пространство
Разделителем слов или полей по умолчанию для разделения любого текста является пробел. Команда awk может принимать текстовое значение в качестве ввода различными способами. Вводимый текст передается из эхо команда в следующем примере. Текст, 'Мне нравится программировать'будет разделен разделителем по умолчанию, космос, и третье слово будет напечатано как вывод.
$ echo 'Я люблю программировать' | awk 'print $ 3'Выход:

Перейти к содержанию
awk, чтобы изменить разделитель
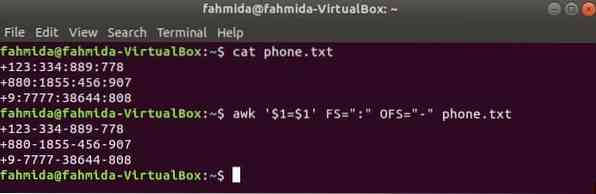
Команда awk может использоваться для изменения разделителя для любого содержимого файла. Предположим, у вас есть текстовый файл с именем Телефон.текст со следующим содержимым, где ':' используется как разделитель полей содержимого файла.
Телефон.текст
+123: 334: 889: 778+880: 1855: 456: 907
+9: 7777: 38644: 808
Выполните следующую команду awk, чтобы изменить разделитель, ':' от '-' к содержанию файла, Телефон.текст.
$ cat телефон.текст$ awk '$ 1 = $ 1' FS = ":" OFS = "-" телефон.текст
Выход:
Перейти к содержанию
awk с данными, разделенными табуляцией
Команда awk имеет множество встроенных переменных, которые используются для чтения текста разными способами. Двое из них FS а также OFS. FS является разделителем поля ввода и OFS переменные-разделители полей вывода. Использование этих переменных показано в этом разделе. Создать вкладка отдельный файл с именем Вход.текст со следующим содержанием для тестирования использования FS а также OFS переменные.
Вход.текст
Клиентский язык сценариевЯзык сценариев на стороне сервера
Сервер базы данных
Веб сервер
Использование переменной FS с вкладкой
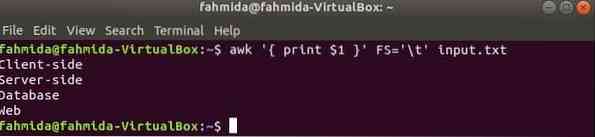
Следующая команда разделит каждую строку Вход.текст файл на основе табуляции ('\ t') и распечатать первое поле каждой строки.
$ awk 'print $ 1' FS = '\ t' ввод.текстВыход:
Использование переменной OFS с вкладкой
Следующая команда awk напечатает 9th а также 5th поля 'ls -l' вывод команды с разделителем табуляции после печати заголовка столбца «Имя" а также "Размер”. Здесь, OFS переменная используется для форматирования вывода вкладкой.
$ ls -l$ ls -l | awk -v OFS = '\ t' 'BEGIN printf "% s \ t% s \ n", "Name", "Size" print $ 9, $ 5'
Выход:

Перейти к содержанию
awk с данными CSV
Содержимое любого CSV-файла можно проанализировать несколькими способами с помощью команды awk. Создайте файл CSV с именем 'клиент.csv'Со следующим содержимым, чтобы применить команду awk.
клиент.текст
Идентификатор, имя, адрес электронной почты, телефон1, София, [адрес электронной почты защищен], (862) 478-7263
2, Амелия, [адрес электронной почты защищен], (530) 764-8000
3, Эмма, [адрес электронной почты защищен], (542) 986-2390
Чтение одного поля файла CSV
'-F' опция используется с командой awk для установки разделителя для разделения каждой строки файла. Следующая команда awk напечатает название поле клиент.csv файл.
$ cat клиент.csv$ awk -F "," 'print $ 2' клиент.csv
Выход: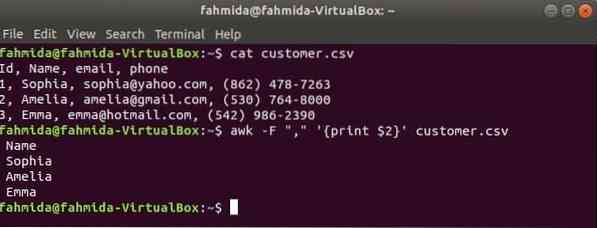
Чтение нескольких полей путем объединения с другим текстом
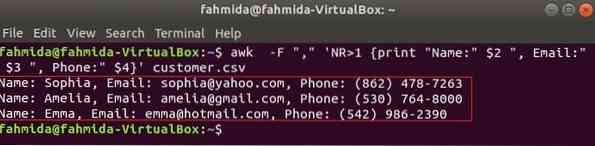
Следующая команда напечатает три поля клиент.csv путем объединения текста заголовка, Имя, адрес электронной почты и телефон. Первая строка клиент.csv файл содержит заголовок каждого поля. NR переменная содержит номер строки файла, когда команда awk анализирует файл. В этом примере, NR переменная используется для пропуска первой строки файла. На выходе будет показано 2nd, 3rd и 4th поля всех строк, кроме первой.
$ awk -F "," 'NR> 1 print "Имя:" $ 2 ", электронная почта:" $ 3 ", телефон:" $ 4 "клиент.csvВыход:
Чтение файла CSV с помощью сценария awk
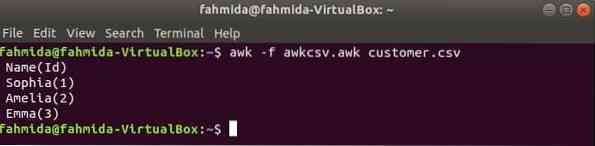
Сценарий awk можно запустить, запустив файл awk. В этом примере показано, как создать файл awk и запустить его. Создайте файл с именем awkcsv.awk со следующим кодом. НАЧИНАТЬ ключевое слово используется в сценарии для информирования команды awk о выполнении сценария НАЧИНАТЬ сначала часть перед выполнением других задач. Здесь разделитель полей (FS) используется для определения разделителя разделения и 2nd и 1ул поля будут напечатаны в соответствии с форматом, используемым в функции printf ().
awkcsv.awkНАЧАТЬ FS = "," printf "% 5s (% s) \ n", $ 2, $ 1
Запустить awkcsv.awk файл с содержанием клиент.csv файл с помощью следующей команды.
$ awk -f awkcsv.клиент awk.csvВыход:
Перейти к содержанию
регулярное выражение awk
Регулярное выражение - это шаблон, который используется для поиска любой строки в тексте. С помощью регулярного выражения можно очень легко выполнить различные типы сложных задач поиска и замены. В этом разделе показаны некоторые простые способы использования регулярного выражения с командой awk.
Соответствующий набор символовСледующая команда будет соответствовать слову Дурак или буг или же Прохладный со входной строкой и вывести, если слово найдено. Здесь, Кукла не будет совпадать и не печатать.
$ printf "Дурак \ nCool \ nDoll \ nbool" | awk '/ [FbC] ool /'Выход:

Строка поиска в начале строки
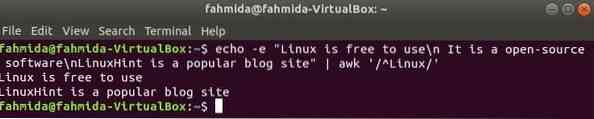
'^' символ используется в регулярном выражении для поиска любого шаблона в начале строки. 'Linux ' слово будет искать в начале каждой строки текста в следующем примере. Здесь две строки начинаются с текста, 'Linux'и эти две строки будут показаны в выводе.
$ echo -e "Linux можно использовать бесплатно \ n Это программное обеспечение с открытым исходным кодом \ nLinuxHint - этопопулярный блог-сайт "| awk '/ ^ Linux /'
Выход:
Строка поиска в конце строки
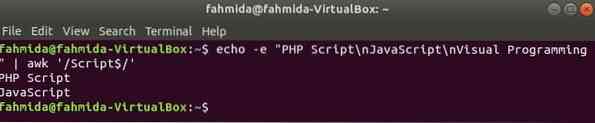
'$' символ используется в регулярном выражении для поиска любого шаблона в конце каждой строки текста. 'Сценарий'слово ищется в следующем примере. Здесь две строки содержат слово, Сценарий в конце строки.
$ echo -e "PHP-скрипт \ nJavaScript \ nВизуальное программирование" | awk '/ сценарий $ /'Выход:
Поиск с пропуском определенного набора символов
'^' символ указывает начало текста, когда он используется перед любым строковым шаблоном ('/ ^… /') или перед любым набором символов, объявленным ^ […]. Если '^' символ используется внутри третьей скобки, [^…] тогда определенный набор символов внутри скобки будет опущен во время поиска. Следующая команда будет искать любое слово, которое не начинается с 'F' но заканчивая 'оол'. Прохладный а также bool будут напечатаны по выкройке и текстовым данным.
$ printf "Дурак \ nCool \ nDoll \ nbool" | awk '/ [^ F] оол /'Выход:

Перейти к содержанию
регулярное выражение без учета регистра в awk
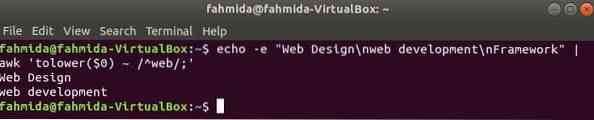
По умолчанию регулярное выражение выполняет поиск с учетом регистра при поиске любого шаблона в строке. Поиск без учета регистра может быть выполнен командой awk с регулярным выражением. В следующем примере, понижать() функция используется для поиска без учета регистра. Здесь первое слово каждой строки входного текста будет преобразовано в нижний регистр с использованием понижать() функция и совпадение с шаблоном регулярного выражения. toupper () для этой цели также можно использовать функцию, в этом случае образец должен определяться всеми заглавными буквами. Текст, определенный в следующем примере, содержит искомое слово, 'сеть'в две строки, которые будут напечатаны как выходные.
$ echo -e "Веб-дизайн \ nвеб-разработка \ nФреймворк" | awk 'tolower ($ 0) ~ / ^ web /;'Выход:
Перейти к содержанию
awk с переменной NF (количество полей)
NF - встроенная переменная команды awk, которая используется для подсчета общего количества полей в каждой строке входного текста. Создайте любой текстовый файл с несколькими строками и несколькими словами. вход.текст здесь используется файл, созданный в предыдущем примере.
Использование NF из командной строки
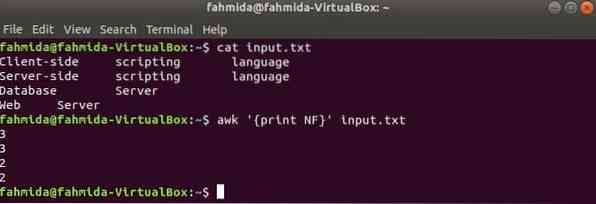
Здесь первая команда используется для отображения содержимого Вход.текст файл, а вторая команда используется для отображения общего количества полей в каждой строке файла, используя NF Переменная.
$ cat ввод.текст$ awk 'print NF' input.текст
Выход:
Использование NF в файле awk
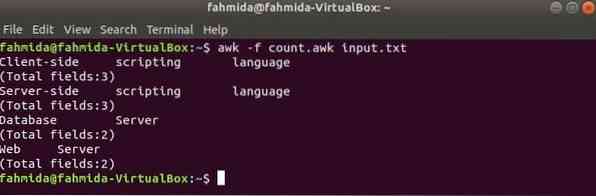
Создайте файл awk с именем считать.awk со сценарием, приведенным ниже. Когда этот скрипт будет выполняться с любыми текстовыми данными, тогда содержимое каждой строки с полными полями будет напечатано как вывод.
считать.awk
print $ 0print "[Всего полей:" NF "]"
Запустите сценарий с помощью следующей команды.
$ awk -f количество.ввод awk.текстВыход:
Перейти к содержанию
функция awk gensub ()
getsub () это функция подстановки, которая используется для поиска строки на основе определенного разделителя или шаблона регулярного выражения. Эта функция определена в 'таращиться' пакет, который не установлен по умолчанию. Синтаксис этой функции приведен ниже. Первый параметр содержит шаблон регулярного выражения или разделитель поиска, второй параметр содержит текст замены, третий параметр указывает, как будет выполняться поиск, а последний параметр содержит текст, в котором будет применяться эта функция.
Синтаксис:
gensub (регулярное выражение, замена, как [, цель])Выполните следующую команду для установки таращиться пакет для использования getsub () функция с командой awk.
$ sudo apt-get install gawkСоздайте текстовый файл с именем 'salesinfo.текст'со следующим содержанием, чтобы попрактиковаться в этом примере. Здесь поля разделены табуляцией.
salesinfo.текст
Пн 700000Вт 800000
Ср 750000
Чт 200000
Пт 430000
Сб 820000
Выполните следующую команду, чтобы прочитать числовые поля salesinfo.текст файл и распечатайте общую сумму продаж. Здесь третий параметр, «G», указывает на глобальный поиск. Это означает, что поиск шаблона будет выполняться во всем содержимом файла.
$ awk 'x = gensub ("\ t", "", "G", $ 2); printf x "+" END print 0 'salesinfo.txt | bc -lВыход:

Перейти к содержанию
awk с функцией rand ()
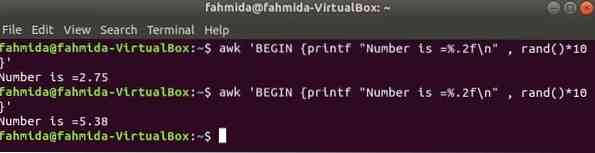
rand () функция используется для генерации любого случайного числа больше 0 и меньше 1. Таким образом, он всегда будет генерировать дробное число меньше 1. Следующая команда сгенерирует дробное случайное число и умножит значение на 10, чтобы получить число больше 1. Дробное число с двумя цифрами после десятичной точки будет напечатано для применения функции printf (). Если вы запустите следующую команду несколько раз, вы будете каждый раз получать разные выходные данные.
$ awk 'BEGIN printf "Число =%.2f \ n ", rand () * 10 'Выход:
Перейти к содержанию
пользовательская функция awk
Все функции, которые использовались в предыдущих примерах, являются встроенными функциями. Но вы можете объявить пользовательскую функцию в своем сценарии awk для выполнения любой конкретной задачи. Предположим, вы хотите создать специальную функцию для вычисления площади прямоугольника. Для выполнения этой задачи создайте файл с именем 'область.awk'со следующим сценарием. В этом примере пользовательская функция с именем область() объявлен в скрипте, который вычисляет площадь на основе входных параметров и возвращает значение площади. Getline команда используется здесь для получения ввода от пользователя.
область.awk
# Рассчитать площадьфункциональная область (высота, ширина)
высота возврата * ширина
# Запускает выполнение
НАЧИНАТЬ
print "Введите значение высоты:"
Getline H < "-"
print "Введите значение ширины:"
Getline W < "-"
print "Area =" area (h, w)
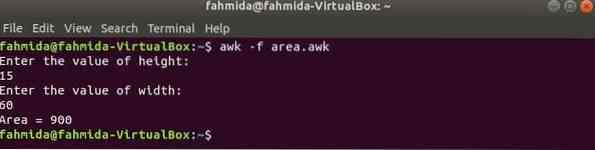
Запускаем скрипт.
$ awk -f область.awkВыход:
Перейти к содержанию
awk если пример
awk поддерживает условные операторы, как и другие стандартные языки программирования. В этом разделе показаны три типа операторов if на трех примерах. Создайте текстовый файл с именем Предметы.текст со следующим содержанием.
Предметы.текст
Жесткий диск Samsung $ 100Мышь A4Tech
Принтер HP $ 200
Простой пример if:
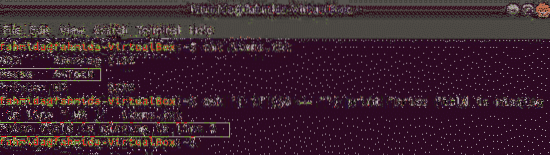
следующая команда прочитает содержимое Предметы.текст файл и проверьте 3rd значение поля в каждой строке. Если значение пусто, будет выведено сообщение об ошибке с номером строки.
$ awk 'if ($ 3 == "") print "Поле цены отсутствует в строке" NR ".текстВыход:
if-else пример:
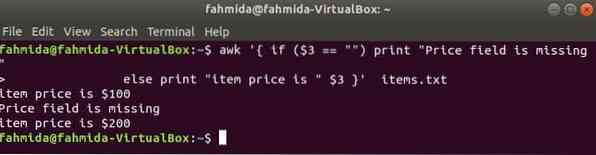
Следующая команда напечатает цену товара, если 3rd поле существует в строке, иначе будет выведено сообщение об ошибке.
$ awk 'if ($ 3 == "") print "Поле цены отсутствует"else print "item price is" $ 3 "товаров.текст
Выход:
if-else-if пример:
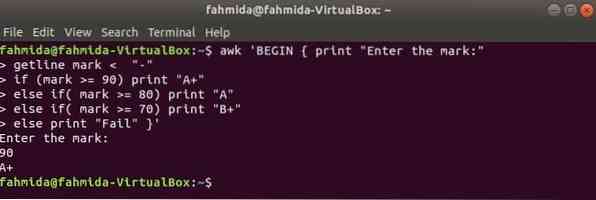
Когда следующая команда будет выполняться с терминала, она будет принимать ввод от пользователя. Входное значение будет сравниваться с каждым условием if, пока условие не станет истинным. Если какое-либо условие станет истинным, будет выведена соответствующая оценка. Если входное значение не совпадает с каким-либо условием, печать будет неудачной.
$ awk 'BEGIN print "Enter the mark:"отметка Getline < "-"
if (mark> = 90) выведите "A +"
иначе, если (отметка> = 80) выведите "A"
иначе, если (отметка> = 70) выведите "B +"
else print "Fail" '
Выход:
Перейти к содержанию
переменные awk
Объявление переменной awk аналогично объявлению переменной оболочки. Есть разница в чтении значения переменной. Символ '$' используется с именем переменной, чтобы переменная оболочки считывала значение. Но нет необходимости использовать '$' с переменной awk для чтения значения.
Используя простую переменную:
Следующая команда объявит переменную с именем 'сайт' и этой переменной присваивается строковое значение. Значение переменной печатается в следующем операторе.
$ awk 'НАЧАТЬ site = "LinuxHint.com "; сайт печати 'Выход:

Использование переменной для извлечения данных из файла
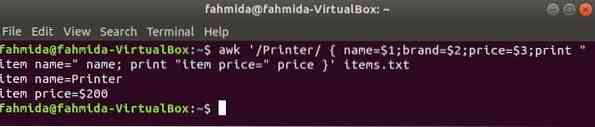
Следующая команда будет искать слово 'Принтер' в файле Предметы.текст. Если какая-либо строка файла начинается с 'Принтер'тогда он сохранит значение 1ул, 2nd а также 3rd поля в три переменные. название а также цена переменные будут напечатаны.
$ awk '/ Принтер / name = $ 1; brand = $ 2; price = $ 3; print "item name =" name;распечатать элементы "item price =" price '.текст
Выход:
Перейти к содержанию
массивы awk
В awk можно использовать как числовые, так и связанные массивы. Объявление переменной массива в awk аналогично другим языкам программирования. Некоторые варианты использования массивов показаны в этом разделе.
Ассоциативный массив:
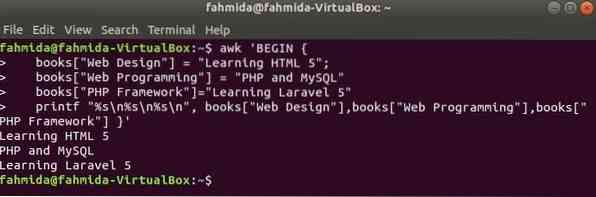
Индексом массива будет любая строка для ассоциативного массива. В этом примере объявляется и печатается ассоциативный массив из трех элементов.
$ awk 'BEGINbooks ["Веб-дизайн"] = "Изучение HTML 5";
books ["Веб-программирование"] = "PHP и MySQL"
books ["PHP Framework"] = "Изучение Laravel 5"
printf "% s \ n% s \ n% s \ n", книги ["Веб-дизайн"], книги ["Веб-программирование"],
книги ["PHP Framework"] '
Выход:
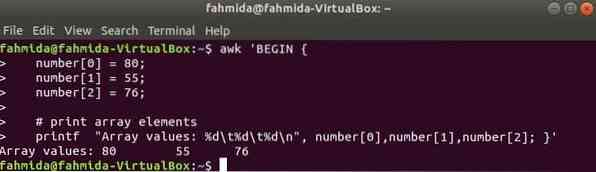
Числовой массив:
Числовой массив из трех элементов объявляется и печатается разделением табуляции.
$ awk 'BEGINчисло [0] = 80;
число [1] = 55;
число [2] = 76;
# выводить элементы массива
printf "Значения массива:% d \ t% d \ t% d \ n", число [0], число [1], число [2]; '
Выход:
Перейти к содержанию
цикл awk
Awk поддерживает три типа циклов. Использование этих циклов показано здесь на трех примерах.
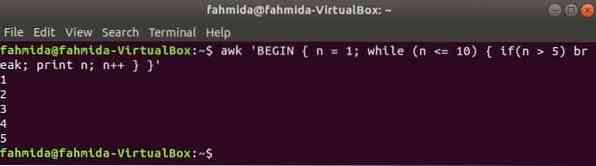
Пока цикл:
Цикл while, который используется в следующей команде, будет повторяться 5 раз и выйдет из цикла для оператора break.
$ Awk 'НАЧАТЬ n = 1; в то время как (п <= 10) if(n > 5) перерыв; print n; n ++ 'Выход:
Для цикла:
Цикл For, который используется в следующей команде awk, вычислит сумму от 1 до 10 и распечатает значение.
$ awk 'НАЧАТЬ сумма = 0; для (n = 1; n <= 10; n++) sum=sum+n; print sum 'Выход:

Цикл Do-while:
цикл do-while следующей команды напечатает все четные числа от 10 до 5.
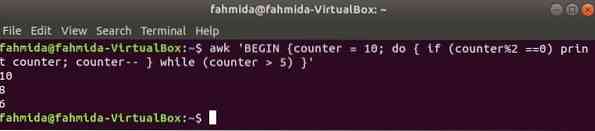
$ awk 'НАЧАЛО counter = 10; do if (counter% 2 == 0) print counter; прилавок--while (counter> 5) '
Выход:
Перейти к содержанию
awk для печати первого столбца
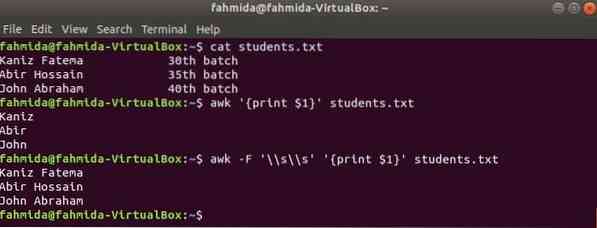
Первый столбец любого файла можно распечатать, используя переменную $ 1 в awk. Но если значение первого столбца содержит несколько слов, то печатается только первое слово первого столбца. Используя определенный разделитель, можно правильно напечатать первый столбец. Создайте текстовый файл с именем студенты.текст со следующим содержанием. Здесь первый столбец содержит текст из двух слов.
Студенты.текст
Каниз Фатема 30th партияAbir Hossain 35th партия
Иоанна Авраама 40th партия
Запустить команду awk без разделителя. Будет напечатана первая часть первого столбца.
$ awk 'print $ 1' ученики.текстЗапустите команду awk со следующим разделителем. Будет напечатана вся часть первой колонки.
$ awk -F '\\ s \\ s' 'print $ 1' ученики.текстВыход:
Перейти к содержанию
awk для печати последнего столбца
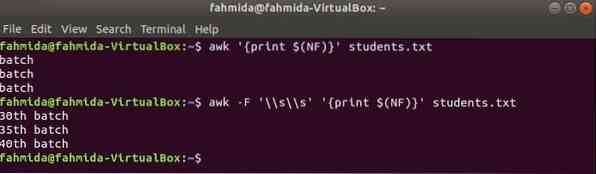
$ (NF) переменную можно использовать для печати последнего столбца любого файла. Следующие команды awk напечатают последнюю и полную часть последнего столбца таблицы студенты.текст файл.
$ awk 'print $ (NF)' ученики.текст$ awk -F '\\ s \\ s' 'print $ (NF)' ученики.текст
Выход:
Перейти к содержанию
awk с grep
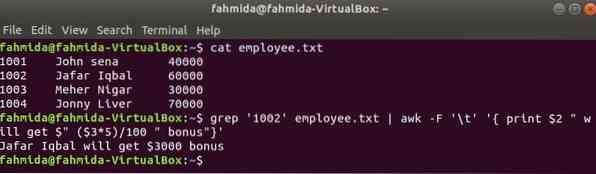
grep - еще одна полезная команда Linux для поиска содержимого в файле на основе любого регулярного выражения. Как команды awk и grep могут использоваться вместе, показано в следующем примере. grep команда используется для поиска информации об идентификаторе сотрудника, '1002' из работник.текст файл. Вывод команды grep будет отправлен в awk в качестве входных данных. Бонус 5% будет подсчитан и распечатан на основе заработной платы сотрудника id »,1002 ' командой awk.
сотрудник $ cat.текстСотрудник $ grep '1002'.txt | awk -F '\ t' 'print $ 2 "получит $" (3 $ * 5) / 100 "бонус"'
Выход:
Перейти к содержанию
awk с файлом BASH
Как и другие команды Linux, команда awk также может использоваться в сценарии BASH. Создайте текстовый файл с именем клиенты.текст со следующим содержанием. Каждая строка этого файла содержит информацию о четырех полях. Это идентификатор клиента, имя, адрес и номер мобильного телефона, разделенные знаком '/'.
клиенты.текст
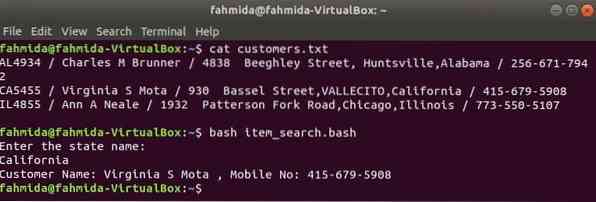
AL4934 / Charles M Brunner / 4838 Beeghley Street, Хантсвилл, Алабама / 256-671-7942CA5455 / Virginia S Mota / 930 Bassel Street, VALLECITO, California / 415-679-5908
IL4855 / Ann A Neale / 1932 Patterson Fork Road, Чикаго, Иллинойс / 773-550-5107
Создайте файл bash с именем item_search.трепать со следующим сценарием. Согласно этому скрипту, значение состояния будет взято у пользователя и найдено в потребители.текст файл grep команда и передается команде awk в качестве входных данных. Команда awk будет читать 2nd а также 4th поля каждой строки. Если входное значение совпадает с любым значением состояния клиенты.текст файл, затем он распечатает клиентский название а также номер мобильного, в противном случае он напечатает сообщение «Заказчик не найден”.
item_search.трепать
#!/ bin / bashecho "Введите название штата:"
читать состояние
customers = 'grep "$ state" клиенты.txt | awk -F "/" 'print "Имя клиента:" $ 2, ",
Мобильный №: "$ 4"
если ["$ customers" !знак равно тогда
echo $ customers
еще
echo «Заказчик не найден»
фи
Выполните следующие команды, чтобы показать выходы.
$ cat клиенты.текст$ bash item_search.трепать
Выход:
Перейти к содержанию
awk с sed
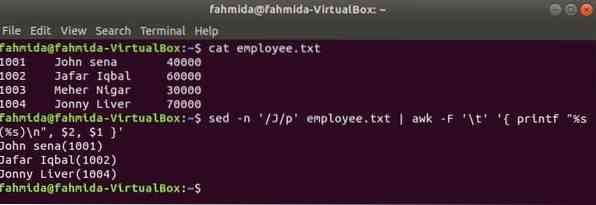
Еще один полезный инструмент поиска в Linux - sed. Эта команда может использоваться как для поиска, так и для замены текста любого файла. В следующем примере показано использование команды awk с sed команда. Здесь команда sed будет искать все имена сотрудников, начинающиеся с 'J'и передается команде awk в качестве входных данных. awk напечатает сотрудника название а также Я БЫ после форматирования.
сотрудник $ cat.текст$ sed -n '/ J / p' сотрудник.txt | awk -F '\ t' 'printf "% s (% s) \ n", $ 2, $ 1'
Выход:
Перейти к содержанию
Заключение:
Вы можете использовать команду awk для создания различных типов отчетов на основе любых табличных данных или данных с разделителями после правильной фильтрации данных. Надеюсь, вы сможете узнать, как работает команда awk, попрактиковавшись в примерах, показанных в этом руководстве.


