Большие данные - это данные порядка терабайт или петабайт и более, состоящие из интеллектуального анализа данных, анализа и прогнозного моделирования больших наборов данных. Быстрый рост информационных и технологических разработок предоставил уникальную возможность для частных лиц и предприятий по всему миру получать прибыль и развивать новые возможности, переопределяющие традиционные бизнес-модели с использованием крупномасштабной аналитики.
В этой статье представлен обзор пяти самых популярных платформ данных с открытым исходным кодом с высоты птичьего полета. Вот наш список:
Apache Hadoop
Apache Hadoop - это программная платформа с открытым исходным кодом, которая обрабатывает очень большие наборы данных в распределенной среде с точки зрения хранения и вычислительной мощности, и в основном построена на недорогом стандартном оборудовании.
Apache Hadoop разработан для простого масштабирования с нескольких до тысяч серверов. Это помогает вам обрабатывать локально сохраненные данные в общей настройке параллельной обработки. Одним из преимуществ Hadoop является то, что он обрабатывает сбои на программном уровне. На следующем рисунке показана общая архитектура экосистемы Hadoop и места, где в ней находятся различные фреймворки:
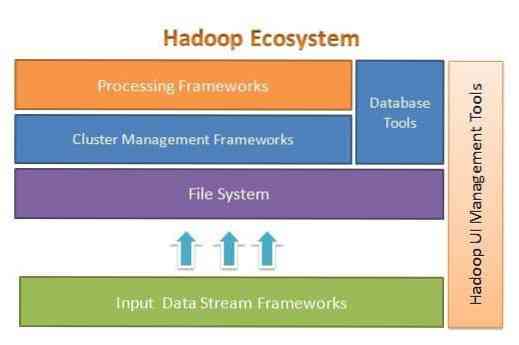
Apache Hadoop предоставляет основу для уровня файловой системы, уровня управления кластером и уровня обработки. Это оставляет возможность другим проектам и фреймворкам работать вместе с Hadoop Ecosystem и разрабатывать свою собственную структуру для любого из уровней, доступных в системе.
Apache Hadoop состоит из четырех основных модулей. Этими модулями являются распределенная файловая система Hadoop (уровень файловой системы), Hadoop MapReduce (который работает как с управлением кластером, так и с уровнем обработки), еще один механизм согласования ресурсов (YARN, уровень управления кластером) и Hadoop Common.
Elasticsearch
Elasticsearch - это система полнотекстового поиска и аналитики. Это хорошо масштабируемая и распределенная система, специально разработанная для эффективной и быстрой работы с системами больших данных, где одним из основных вариантов использования является анализ журналов. Он способен выполнять расширенный и сложный поиск, а также обрабатывать данные почти в реальном времени для расширенной аналитики и оперативной аналитики.
Elasticsearch написан на Java и основан на Apache Lucene. Выпущенный в 2010 году, он быстро завоевал популярность благодаря гибкой структуре данных, масштабируемой архитектуре и очень быстрому времени отклика. Elasticsearch основан на документе JSON со структурой без схем, что упрощает внедрение. Это одна из ведущих поисковых систем корпоративного уровня. Вы можете написать своего клиента на любом языке программирования; Elasticsearch официально работает с Java, .NET, PHP, Python, Perl и т. Д.
Elasticsearch в основном взаимодействует с REST API. Он получает данные в виде документов JSON со всеми необходимыми параметрами и аналогичным образом предоставляет свой ответ.
MongoDB
MongoDB - это база данных NoSQL, основанная на модели данных хранилища документов. В MongoDB все либо коллекция, либо документ. Чтобы понять терминологию MongoDB, коллекция - это альтернативное слово для таблицы, тогда как документ - это альтернативное слово для строк.
MongoDB - это кроссплатформенная база данных с открытым исходным кодом, ориентированная на документы. Он в основном написан на C++. Это также ведущая база данных NoSQL, которая обеспечивает высокую производительность, доступность и простую масштабируемость. MongoDB использует JSON-подобные документы со схемой и предоставляет широкую поддержку запросов. Некоторые из основных функций включают индексацию, репликацию, балансировку нагрузки, агрегацию и хранение файлов.
Кассандра
Cassandra - это проект Apache с открытым исходным кодом, предназначенный для управления базами данных NoSQL. Строки Cassandra организованы в таблицы и индексируются ключом. Он использует механизм хранения на основе журналов только с добавлением. Данные в Cassandra распределяются по нескольким узлам без мастера, без единой точки отказа. Это проект Apache верхнего уровня, и его разработка в настоящее время контролируется Apache Software Foundation (ASF).
Cassandra предназначена для решения проблем, связанных с работой в большом (веб) масштабе. Учитывая архитектуру Cassandra без мастера, она может продолжать выполнять операции, несмотря на небольшое (хотя и значительное) количество аппаратных сбоев. Cassandra работает на нескольких узлах в нескольких центрах обработки данных. Он реплицирует данные в этих центрах обработки данных, чтобы избежать сбоев или простоев. Это делает систему очень отказоустойчивой.
Cassandra использует собственный язык программирования для доступа к данным через свои узлы. Он называется Cassandra Query Language или CQL. Он похож на SQL, который в основном используется реляционными базами данных. CQL можно использовать, запустив собственное приложение под названием cqlsh. Cassandra также предоставляет множество интерфейсов интеграции для нескольких языков программирования для создания приложения с использованием Cassandra. Его интеграционный API поддерживает Java, C ++, Python и другие.
Apache HBase
HBase - еще один проект Apache, предназначенный для управления хранилищем данных NoSQL. Он предназначен для использования функций Hadoop Ecosystem, включая надежность, отказоустойчивость и т. Д. Он использует HDFS в качестве файловой системы для хранения. Существует несколько моделей данных, с которыми работает NoSQL, и Apache HBase относится к модели данных, ориентированной на столбцы. HBase изначально был основан на Google Big Table, которая также связана с моделью столбцов для неструктурированных данных.
HBase хранит все в виде пары ключ-значение. Важно отметить, что в HBase ключ и значение имеют форму байтов. Итак, чтобы хранить любую информацию в HBase, вам нужно преобразовать информацию в байты. (Другими словами, его API не принимает ничего, кроме массива байтов.) Будьте осторожны с HBase, так как при сохранении данных вы должны помнить их исходный тип. Данные, которые изначально были строкой, будут возвращены как массив байтов, если вызваны неправильно. В результате это создаст ошибку в вашем приложении и приведет к сбою вашего приложения.
Надеюсь, вам понравилась эта статья. Если вы хотите создавать и проектировать приложения, интенсивно использующие данные, вы можете изучить статью Ануджа Кумара Архитектура приложений, интенсивно использующих данные. Этот книга это ваш шлюз для создания интеллектуальных систем с интенсивным использованием данных путем включения основных архитектурных принципов, шаблонов и методов обработки данных непосредственно в архитектуру вашего приложения.

