Когда мы говорим о распределенных системах, как указано выше, мы сталкиваемся с проблемой аналитики и мониторинга. Каждый узел генерирует много информации о своем собственном состоянии (использование ЦП, память и т. Д.) И о статусе приложения, а также о том, что пользователи пытаются сделать. Эти данные должны быть записаны в:
- В том же порядке, в котором они созданы,
- Разделены с точки зрения срочности (аналитика в реальном времени или пакеты данных) и, что наиболее важно,
- Механизм, с помощью которого они собираются, должен быть сам по себе распределенным и масштабируемым, иначе мы останемся с единой точкой отказа. Что-то, чего должен был избежать дизайн распределенной системы.
Зачем использовать Kafka?
Apache Kafka позиционируется как распределенная потоковая платформа. На языке кафка, Продюсеры непрерывно генерировать данные (потоки) а также Потребители несут ответственность за его обработку, хранение и анализ. Кафка Брокеры несут ответственность за обеспечение того, чтобы в распределенном сценарии данные могли доходить от производителей к потребителям без какой-либо несогласованности. Набор брокеров Kafka и другое программное обеспечение под названием работник зоопарка представляют собой типичное развертывание Kafka.
Поток данных от многих производителей необходимо агрегировать, разделять и отправлять нескольким потребителям, при этом требуется много перетасовки. Избежать непоследовательности - непростая задача. Вот почему нам нужен Кафка.
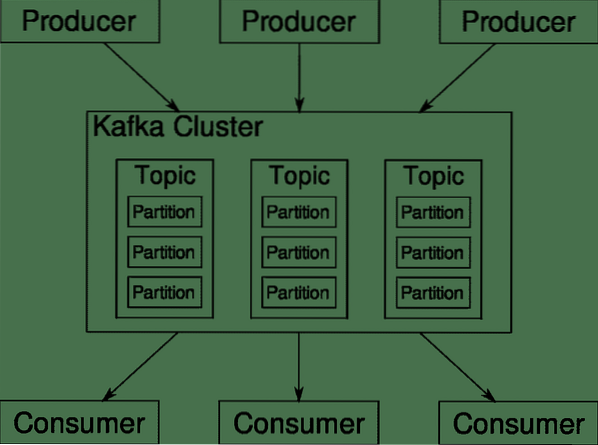
Сценарии, в которых можно использовать Kafka, довольно разнообразны. Все, что угодно, от устройств IOT до кластера виртуальных машин и ваших собственных локальных серверов без операционной системы. В любом месте, где много "вещей" одновременно требуют вашего внимания… .Это не очень научно, не так ли? Что ж, архитектура Кафки - это сама по себе кроличья нора и заслуживает отдельного рассмотрения. Давайте сначала рассмотрим развертывание программного обеспечения на очень поверхностном уровне.
Использование Docker Compose
Каким бы изобретательным способом вы ни решили использовать Kafka, одно можно сказать наверняка - вы не будете использовать его как единичный экземпляр. Он не предназначен для использования таким образом, и даже если вашему распределенному приложению на данный момент нужен только один экземпляр (брокер), он в конечном итоге будет расти, и вам нужно убедиться, что Kafka может не отставать.
Docker-compose - идеальный партнер для такого рода масштабируемости. Вместо того, чтобы запускать брокеры Kafka на разных виртуальных машинах, мы помещаем их в контейнер и используем Docker Compose для автоматизации развертывания и масштабирования. Контейнеры Docker хорошо масштабируются как на отдельных хостах Docker, так и в кластере, если мы используем Docker Swarm или Kubernetes. Поэтому имеет смысл использовать его, чтобы сделать Kafka масштабируемым.
Начнем с одного экземпляра брокера. Создайте каталог с именем apache-kafka и внутри него создайте свой docker-compose.yml.
$ mkdir apache-kafka$ cd apache-kafka
$ vim docker-compose.yml
Следующее содержимое будет помещено в ваш docker-compose.yml файл:
версия: '3'Сервисы:
работник зоопарка:
изображение: wurstmeister / zookeeper
кафка:
изображение: wurstmeister / kafka
порты:
- «9092: 9092»
среда:
KAFKA_ADVERTISED_HOST_NAME: локальный хост
KAFKA_ZOOKEEPER_CONNECT: смотритель: 2181
После того, как вы сохранили вышеуказанное содержимое в своем файле создания, из того же каталога запустите:
$ docker-compose up -dХорошо, так что мы здесь делали?
Понимание Docker-Compose.yml
Compose запустит две службы, перечисленные в файле yml. Посмотрим на файл немного внимательнее. Первый образ - это zookeeper, который Kafka требует для отслеживания различных брокеров, топологии сети, а также для синхронизации другой информации. Так как службы zookeeper и kafka будут частью одной и той же сети моста (она создается, когда мы запускаем docker-compose up), нам не нужно открывать какие-либо порты. Брокер Kafka может разговаривать с zookeeper, и это все, что нужно zookeeper для общения.
Вторая служба - это сама кафка, и мы запускаем ее только один экземпляр, то есть один брокер. В идеале вы хотели бы использовать несколько брокеров, чтобы использовать распределенную архитектуру Kafka. Служба прослушивает порт 9092, который сопоставлен с тем же номером порта на хосте Docker, и именно так служба взаимодействует с внешним миром.
Второй сервис также имеет пару переменных окружения. Во-первых, для KAFKA_ADVERTISED_HOST_NAME установлено значение localhost. Это адрес, по которому работает Kafka, и где его могут найти производители и потребители. Еще раз, это должно быть установлено на localhost, а скорее на IP-адрес или имя хоста, с которыми серверы могут быть доступны в вашей сети. Во-вторых, это имя хоста и номер порта вашей службы zookeeper. Поскольку мы назвали службу zookeeper ... ну, zookeeper - это то, что будет именем хоста в сети docker bridge, о которой мы упоминали.
Запуск простого потока сообщений
Для того, чтобы Kafka заработал, нам нужно создать в нем тему. Затем клиенты-производители могут публиковать потоки данных (сообщений) в указанную тему, а потребители могут читать указанный поток данных, если они подписаны на эту конкретную тему.
Для этого нам нужно запустить интерактивный терминал с контейнером Kafka. Перечислите контейнеры для получения имени контейнера kafka. Например, в этом случае наш контейнер называется apache-kafka_kafka_1
$ docker psТеперь, используя имя контейнера kafka, мы можем зайти внутрь этого контейнера.
$ docker exec -it apache-kafka_kafka_1 bashбаш-4.4 #
Откройте два таких разных терминала, чтобы использовать один в качестве потребителя, а другой - производителя.
Сторона продюсера
В одном из запросов (тот, который вы выбрали в качестве производителя) введите следующие команды:
## Чтобы создать новую тему под названием testбаш-4.4 # kafka-themes.sh --create --zookeeper zookeeper: 2181 - коэффициент репликации 1
--разделы 1 - тематический тест
## Для запуска производителя, который публикует поток данных со стандартного ввода в kafka
баш-4.4 # кафка-консоль-продюсер.sh --broker-list localhost: 9092 --topic test
>
Теперь продюсер готов принять ввод с клавиатуры и опубликовать его.
Потребительская сторона
Перейдите ко второму терминалу, подключенному к вашему контейнеру kafka. Следующая команда запускает потребителя, который питается по тестовой теме:
$ кафка-консоль-потребитель.sh --bootstrap-server localhost: 9092 --topic testВернуться к продюсеру
Теперь вы можете вводить сообщения в новом приглашении, и каждый раз, когда вы нажимаете return, новая строка печатается в приглашении пользователя. Например:
> Это сообщение.Это сообщение передается потребителю через Kafka, и вы можете увидеть его напечатанным в приглашении потребителя.
Настройки в реальном мире
Теперь у вас есть приблизительное представление о том, как работает установка Kafka. Для вашего собственного варианта использования вам необходимо установить имя хоста, которое не является localhost, вам нужно, чтобы несколько таких брокеров были частью вашего кластера kafka, и, наконец, вам нужно настроить клиентов-потребителей и производителей.
Вот несколько полезных ссылок:
- Клиент Confluent на Python
- Официальная документация
- Полезный список демонстраций
Надеюсь, вам понравится знакомство с Apache Kafka.


