В этой статье показано, как найти дубликаты в данных и удалить дубликаты с помощью функций Pandas Python.
В этой статье мы взяли набор данных о населении разных штатов США, который доступен в .формат файла csv. Мы прочитаем .csv, чтобы показать исходное содержимое этого файла, как показано ниже:
импортировать панд как pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / Population_ds.csv ")
печать (df_state)
На следующем снимке экрана вы можете увидеть дублированное содержимое этого файла:
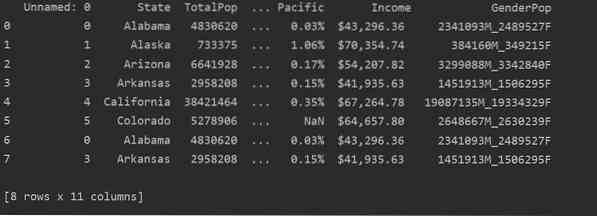
Выявление дубликатов в Pandas Python
Необходимо определить, есть ли в используемых вами данных повторяющиеся строки. Чтобы проверить дублирование данных, вы можете использовать любой из методов, описанных в следующих разделах.
Способ 1:
Прочтите файл csv и передайте его во фрейм данных. Затем определите повторяющиеся строки с помощью дублированный () функция. Наконец, используйте оператор печати для отображения повторяющихся строк.
импортировать панд как pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / Population_ds.csv ")
Dup_Rows = df_state [df_state.дублированный ()]
print ("\ n \ nДублирующие строки: \ n ".формат (Dup_Rows))
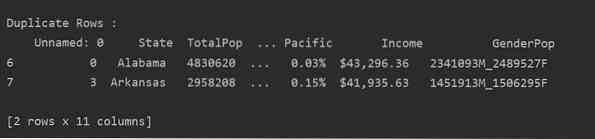
Способ 2:
Используя этот метод, is_duplicated столбец будет добавлен в конец таблицы и помечен как True в случае дублирования строк.
импортировать панд как pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / Population_ds.csv ")
df_state ["is_duplicate"] = df_state.дублированный ()
print ("\ n ".формат (df_state))
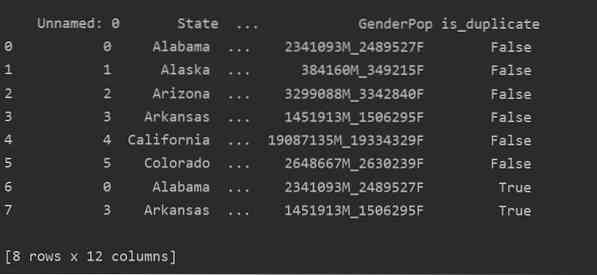
Удаление дубликатов в Pandas Python
Дублированные строки можно удалить из фрейма данных, используя следующий синтаксис:
drop_duplicates (subset = ", keep =", inplace = False)
Вышеуказанные три параметра являются необязательными и более подробно описаны ниже:
хранить: этот параметр имеет три разных значения: First, Last и False. Значение First сохраняет первое вхождение и удаляет последующие дубликаты, значение Last сохраняет только последнее вхождение и удаляет все предыдущие дубликаты, а значение False удаляет все повторяющиеся строки.
подмножество: метка, используемая для идентификации повторяющихся строк
на месте: содержит два условия: True и False. Этот параметр удалит повторяющиеся строки, если для него установлено значение True.
Удалите дубликаты, сохранив только первое вхождение
Когда вы используете «keep = first», будет сохранено только первое вхождение строки, а все остальные дубликаты будут удалены.
Пример
В этом примере будет сохранена только первая строка, а остальные дубликаты будут удалены:
импортировать панд как pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / Population_ds.csv ")
Dup_Rows = df_state [df_state.дублированный ()]
print ("\ n \ nДублирующие строки: \ n ".формат (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (keep = 'первый')
print ('\ n \ nResult DataFrame после удаления дубликатов: \ n', DF_RM_DUP.голова (n = 5))
На следующем снимке экрана сохраненное вхождение первой строки выделено красным, а остальные дубликаты удалены:
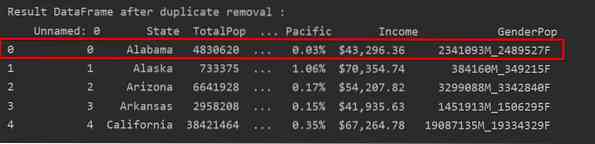
Удаление дубликатов, сохраняя только последнее вхождение
Когда вы используете «keep = last», все повторяющиеся строки, кроме последнего вхождения, будут удалены.
Пример
В следующем примере удаляются все повторяющиеся строки, кроме последнего вхождения.
импортировать панд как pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / Population_ds.csv ")
Dup_Rows = df_state [df_state.дублированный ()]
print ("\ n \ nДублирующие строки: \ n ".формат (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (keep = 'последний')
print ('\ n \ nResult DataFrame после удаления дубликатов: \ n', DF_RM_DUP.голова (n = 5))
На следующем изображении дубликаты удалены, и сохраняется только последнее вхождение строки:
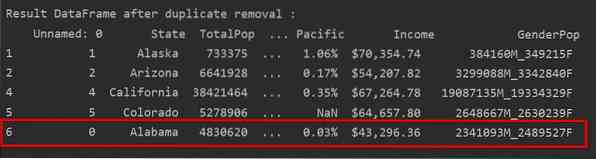
Удалить все повторяющиеся строки
Чтобы удалить все повторяющиеся строки из таблицы, установите «keep = False» следующим образом:
импортировать панд как pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / Population_ds.csv ")
Dup_Rows = df_state [df_state.дублированный ()]
print ("\ n \ nДублирующие строки: \ n ".формат (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (keep = False)
print ('\ n \ nResult DataFrame после удаления дубликатов: \ n', DF_RM_DUP.голова (n = 5))
Как вы можете видеть на следующем изображении, все дубликаты удалены из фрейма данных:
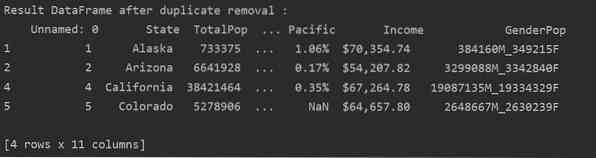
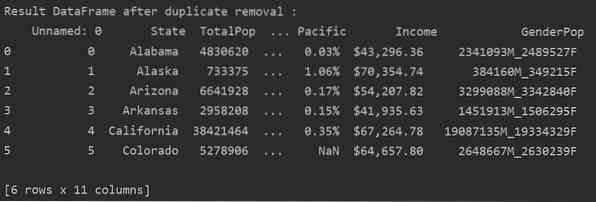
Удалить связанные дубликаты из указанного столбца
По умолчанию функция проверяет все повторяющиеся строки из всех столбцов в заданном фрейме данных. Но вы также можете указать имя столбца с помощью параметра подмножества.
Пример
В следующем примере все связанные дубли удаляются из столбца "Состояния".
импортировать панд как pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / Population_ds.csv ")
Dup_Rows = df_state [df_state.дублированный ()]
print ("\ n \ nДублирующие строки: \ n ".формат (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (subset = 'Состояние')
print ('\ n \ nResult DataFrame после удаления дубликатов: \ n', DF_RM_DUP.голова (n = 6))
Заключение
В этой статье показано, как удалить повторяющиеся строки из фрейма данных с помощью drop_duplicates () функция в Pandas Python. Вы также можете очистить свои данные от дублирования или избыточности с помощью этой функции. В статье также показано, как определять любые дубликаты во фрейме данных.


