В этой статье мы рассмотрим основные способы использования группы по функциям в panda python. Все команды выполняются в редакторе Pycharm.
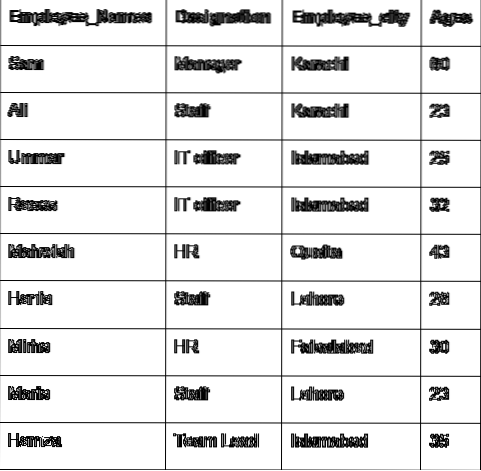
Обсудим основную концепцию группы с помощью данных сотрудника. Мы создали фреймворк с некоторыми полезными данными о сотрудниках (Employee_Names, Designation, Employee_city, Age).
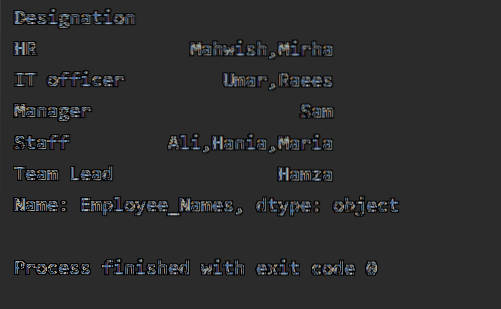
Конкатенация строк с использованием группы по функциям
Используя функцию groupby, вы можете объединять строки. Одни и те же записи могут быть объединены с помощью ',' в одной ячейке.
Пример
В следующем примере мы отсортировали данные на основе столбца «Обозначение сотрудников» и объединили сотрудников с таким же назначением. Лямбда-функция применяется к "Employees_Name".
импортировать панд как pddf = pd.DataFrame (
«Employee_Names»: [«Сэм», «Али», «Умар», «Раис», «Махвиш», «Хания», «Мирха», «Мария», «Хамза»],
«Обозначение»: [«Менеджер», «Персонал», «ИТ-специалист», «ИТ-специалист», «HR», «Персонал», «HR», «Персонал», «Руководитель группы»],
"Employee_city": ["Карачи", "Карачи", "Исламабад", "Исламабад", "Кветта", "Лахор", "Файслабад", "Лахор", "Исламабад"],
"Employee_Age": [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ("Обозначение") ['Employee_Names'].apply (лямбда Employee_Names: ','.присоединиться (Employee_Names))
печать (df1)
Когда приведенный выше код выполняется, отображаются следующие выходные данные:
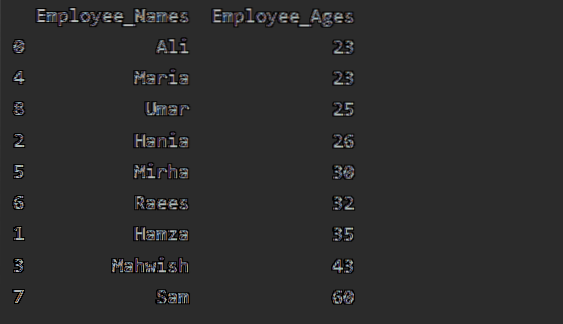
Сортировка значений в порядке возрастания
Используйте объект groupby в обычном фрейме данных, вызвав '.to_frame () ', а затем используйте reset_index () для переиндексации. Сортировка значений столбцов путем вызова sort_values ().
Пример
В этом примере мы отсортируем возраст сотрудника в порядке возрастания. Используя следующий фрагмент кода, мы получили «Employee_Age» в порядке возрастания с «Employee_Names».
импортировать панд как pddf = pd.DataFrame (
«Employee_Names»: [«Сэм», «Али», «Умар», «Раис», «Махвиш», «Хания», «Мирха», «Мария», «Хамза»],
«Обозначение»: [«Менеджер», «Персонал», «ИТ-специалист», «ИТ-специалист», «HR», «Персонал», «HR», «Персонал», «Руководитель группы»],
"Employee_city": ["Карачи", "Карачи", "Исламабад", "Исламабад", "Кветта", "Лахор", "Файслабад", "Лахор", "Исламабад"],
"Employee_Age": [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Employee_Age'].сумма ().к кадру().reset_index ().sort_values (по = 'Employee_Age')
печать (df1)
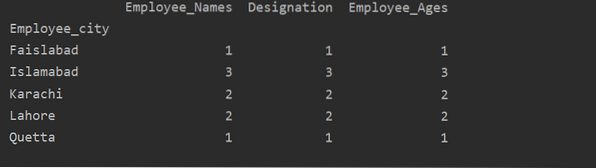
Использование агрегатов с groupby
Доступен ряд функций или агрегатов, которые можно применять к группам данных, например count (), sum (), mean (), median (), mode (), std (), min (), max ().
Пример
В этом примере мы использовали функцию count () с groupby для подсчета сотрудников, принадлежащих к одному и тому же Employee_city.
импортировать панд как pddf = pd.DataFrame (
«Employee_Names»: [«Сэм», «Али», «Умар», «Раис», «Махвиш», «Хания», «Мирха», «Мария», «Хамза»],
«Обозначение»: [«Менеджер», «Персонал», «ИТ-специалист», «ИТ-специалист», «HR», «Персонал», «HR», «Персонал», «Руководитель группы»],
"Employee_city": ["Карачи", "Карачи", "Исламабад", "Исламабад", "Кветта", "Лахор", "Файслабад", "Лахор", "Исламабад"],
"Employee_Age": [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city').считать()
печать (df1)
Как вы можете видеть в следующих выходных данных, в столбцах «Назначение», «Имя сотрудника» и «Возраст сотрудника» подсчитайте числа, принадлежащие одному городу:
Визуализируйте данные с помощью groupby
Используя 'import matplotlib.pyplot ', вы можете визуализировать свои данные в виде графиков.
Пример
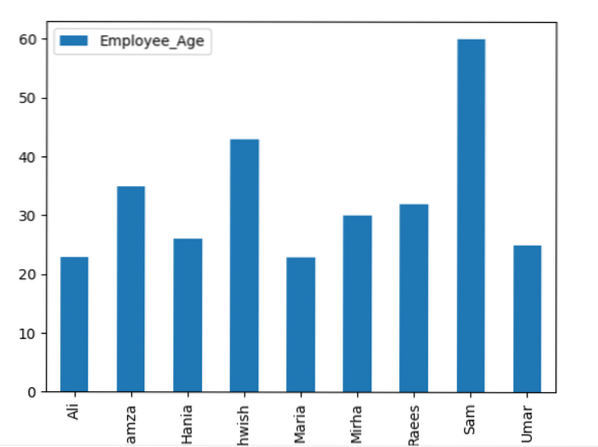
Здесь следующий пример визуализирует «Employee_Age» с «Employee_Nmaes» из заданного DataFrame с помощью оператора groupby.
импортировать панд как pdимпортировать matplotlib.pyplot как plt
dataframe = pd.DataFrame (
«Employee_Names»: [«Сэм», «Али», «Умар», «Раис», «Махвиш», «Хания», «Мирха», «Мария», «Хамза»],
«Обозначение»: [«Менеджер», «Персонал», «ИТ-специалист», «ИТ-специалист», «HR», «Персонал», «HR», «Персонал», «Руководитель группы»],
"Employee_city": ["Карачи", "Карачи", "Исламабад", "Исламабад", "Кветта", "Лахор", "Файслабад", "Лахор", "Исламабад"],
"Employee_Age": [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
фрейм данных.groupby ('Имена сотрудников').сумма ().сюжет (вид = 'бар')
plt.показывать()
Пример
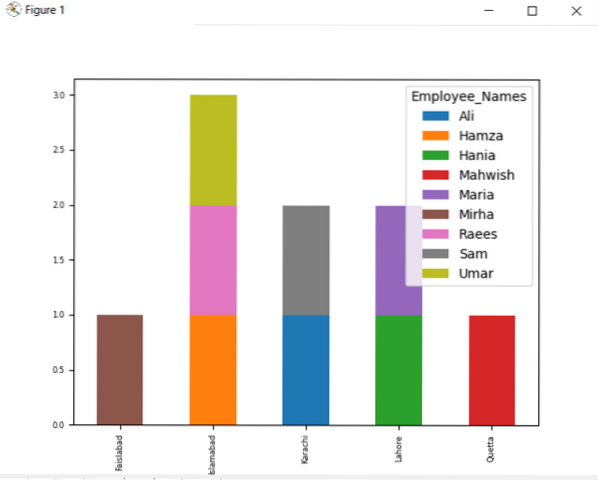
Чтобы построить диаграмму с накоплением с помощью groupby, включите параметр stacked = true и используйте следующий код:
импортировать панд как pdимпортировать matplotlib.pyplot как plt
df = pd.DataFrame (
«Employee_Names»: [«Сэм», «Али», «Умар», «Раис», «Махвиш», «Хания», «Мирха», «Мария», «Хамза»],
«Обозначение»: [«Менеджер», «Персонал», «ИТ-специалист», «ИТ-специалист», «HR», «Персонал», «HR», «Персонал», «Руководитель группы»],
"Employee_city": ["Карачи", "Карачи", "Исламабад", "Исламабад", "Кветта", "Лахор", "Файслабад", "Лахор", "Исламабад"],
"Employee_Age": [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby (['Employee_city', 'Employee_Names']).размер().разложить ().сюжет (kind = 'bar', stacked = True, fontsize = '6')
plt.показывать()
На графике ниже показано количество сотрудников из одного города.
Измените имя столбца с группой по
Вы также можете изменить имя агрегированного столбца на новое измененное имя следующим образом:
импортировать панд как pdимпортировать matplotlib.pyplot как plt
df = pd.DataFrame (
«Employee_Names»: [«Сэм», «Али», «Умар», «Раис», «Махвиш», «Хания», «Мирха», «Мария», «Хамза»],
«Обозначение»: [«Менеджер», «Персонал», «ИТ-специалист», «ИТ-специалист», «HR», «Персонал», «HR», «Персонал», «Руководитель группы»],
"Employee_city": ["Карачи", "Карачи", "Исламабад", "Исламабад", "Кветта", "Лахор", "Файслабад", "Лахор", "Исламабад"],
"Employee_Age": [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
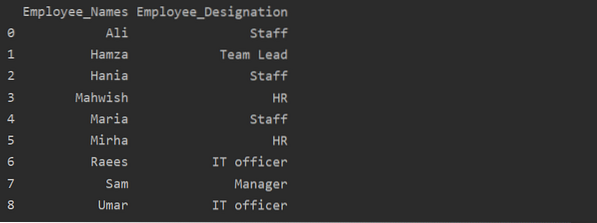
df1 = df.groupby ('Employee_Names') ['Обозначение'].сумма ().reset_index (имя = 'Employee_Designation')
печать (df1)
В приведенном выше примере имя «Обозначение» изменено на «Employee_Designation».
Получить группу по ключу или значению
Используя оператор groupby, вы можете получить похожие записи или значения из фрейма данных.
Пример
В приведенном ниже примере у нас есть групповые данные на основе «Обозначения». Затем группа «Персонал» извлекается с помощью .getgroup ('Персонал').
импортировать панд как pdимпортировать matplotlib.pyplot как plt
df = pd.DataFrame (
«Employee_Names»: [«Сэм», «Али», «Умар», «Раис», «Махвиш», «Хания», «Мирха», «Мария», «Хамза»],
«Обозначение»: [«Менеджер», «Персонал», «ИТ-специалист», «ИТ-специалист», «HR», «Персонал», «HR», «Персонал», «Руководитель группы»],
"Employee_city": ["Карачи", "Карачи", "Исламабад", "Исламабад", "Кветта", "Лахор", "Файслабад", "Лахор", "Исламабад"],
"Employee_Age": [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
extract_value = df.groupby ("Обозначение")
print (extract_value.get_group ('Персонал'))
В окне вывода отображается следующий результат:

Добавить значение в список группы
Подобные данные можно отобразить в виде списка с помощью оператора groupby. Сначала сгруппируйте данные по условию. Затем, применив функцию, вы можете легко поместить эту группу в списки.
Пример
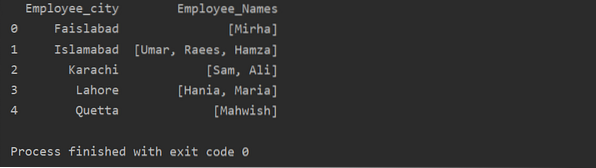
В этом примере мы вставили похожие записи в список группы. Все сотрудники делятся на группы на основе «Employee_city», а затем, применяя функцию «Лямбда», эта группа извлекается в виде списка.
импортировать панд как pddf = pd.DataFrame (
«Employee_Names»: [«Сэм», «Али», «Умар», «Раис», «Махвиш», «Хания», «Мирха», «Мария», «Хамза»],
«Обозначение»: [«Менеджер», «Персонал», «ИТ-специалист», «ИТ-специалист», «HR», «Персонал», «HR», «Персонал», «Руководитель группы»],
"Employee_city": ["Карачи", "Карачи", "Исламабад", "Исламабад", "Кветта", "Лахор", "Файслабад", "Лахор", "Исламабад"],
"Employee_Age": [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].применить (лямбда group_series: group_series.к списку()).reset_index ()
печать (df1)
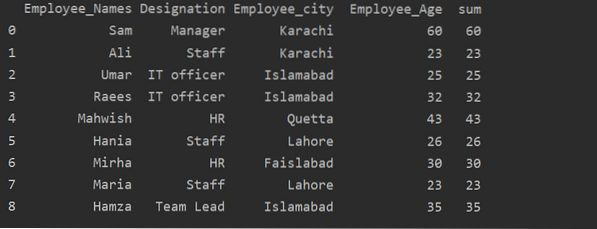
Использование функции преобразования с groupby
Сотрудники группируются по возрасту, эти значения складываются вместе, и с помощью функции преобразования в таблицу добавляется новый столбец:
импортировать панд как pddf = pd.DataFrame (
«Employee_Names»: [«Сэм», «Али», «Умар», «Раис», «Махвиш», «Хания», «Мирха», «Мария», «Хамза»],
«Обозначение»: [«Менеджер», «Персонал», «ИТ-специалист», «ИТ-специалист», «HR», «Персонал», «HR», «Персонал», «Руководитель группы»],
"Employee_city": ["Карачи", "Карачи", "Исламабад", "Исламабад", "Кветта", "Лахор", "Файслабад", "Лахор", "Исламабад"],
"Employee_Age": [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['сумма'] = df.groupby (['Employee_Names']) ['Employee_Age'].преобразовать ('сумма')
печать (df)
Заключение
В этой статье мы исследовали различные варианты использования оператора groupby. Мы показали, как вы можете разделить данные на группы, и, применяя различные агрегаты или функции, вы можете легко получить эти группы.


