Apache Spark - это инструмент анализа данных, который можно использовать для обработки данных из HDFS, S3 или других источников данных в памяти. В этом посте мы установим Apache Spark на Ubuntu 17.10 машина.
Версия Ubuntu
В этом руководстве мы будем использовать Ubuntu версии 17.10 (GNU / Linux 4.13.0-38-общий x86_64).
Apache Spark является частью экосистемы Hadoop для больших данных. Попробуйте установить Apache Hadoop и создать с его помощью образец приложения.
Обновление существующих пакетов
Чтобы начать установку Spark, необходимо обновить наш компьютер с помощью последних доступных пакетов программного обеспечения. Мы можем сделать это с помощью:
sudo apt-get update && sudo apt-get -y dist-upgradeПоскольку Spark основан на Java, нам необходимо установить его на нашу машину. Мы можем использовать любую версию Java выше Java 6. Здесь мы будем использовать Java 8:
sudo apt-get -y установить openjdk-8-jdk-headlessСкачивание файлов Spark
Все необходимые пакеты теперь существуют на нашей машине. Мы готовы загрузить необходимые файлы Spark TAR, чтобы начать их настройку и запустить образец программы со Spark.
В этом руководстве мы будем устанавливать Spark v2.3.0 доступна здесь:
Страница загрузки Spark
Загрузите соответствующие файлы с помощью этой команды:
wget http: // www-us.апач.org / dist / spark / искра-2.3.0 / искра-2.3.0-бин-hadoop2.7.тгзВ зависимости от скорости сети это может занять до нескольких минут, так как файл большой по размеру:
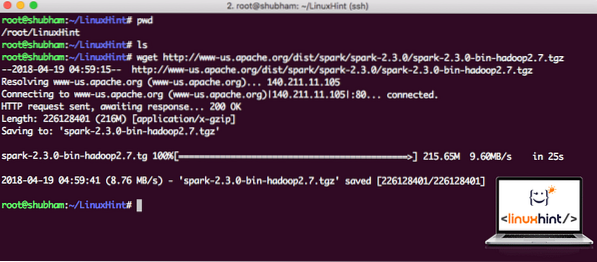
Скачивание Apache Spark
Теперь, когда у нас есть загруженный файл TAR, мы можем извлечь его в текущий каталог:
tar xvzf искра-2.3.0-бин-hadoop2.7.тгзЭто займет несколько секунд из-за большого размера файла архива:
Разархивированные файлы в Spark
Когда дело доходит до обновления Apache Spark в будущем, это может создать проблемы из-за обновлений Path. Этих проблем можно избежать, создав мягкую ссылку на Spark. Выполните эту команду, чтобы создать мягкую ссылку:
ln -s искра-2.3.0-бин-hadoop2.7 искрыДобавление искры в путь
Чтобы выполнить скрипт Spark, мы добавим его в путь сейчас. Для этого откройте файл bashrc:
vi ~ /.bashrcДобавьте эти строки в конец .bashrc, чтобы путь мог содержать путь к исполняемому файлу Spark:
SPARK_HOME = / LinuxHint / искраэкспорт PATH = $ SPARK_HOME / bin: $ PATH
Теперь файл выглядит так:
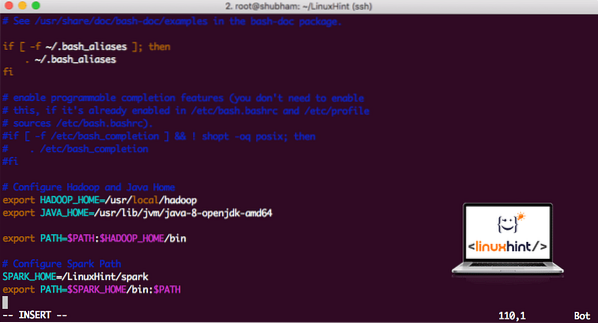
Добавление Spark в PATH
Чтобы активировать эти изменения, выполните следующую команду для файла bashrc:
источник ~ /.bashrcЗапуск Spark Shell
Теперь, когда мы находимся прямо за пределами каталога spark, выполните следующую команду, чтобы открыть оболочку apark:
./ искра / бункер / искровая оболочкаМы увидим, что оболочка Spark теперь открыта:
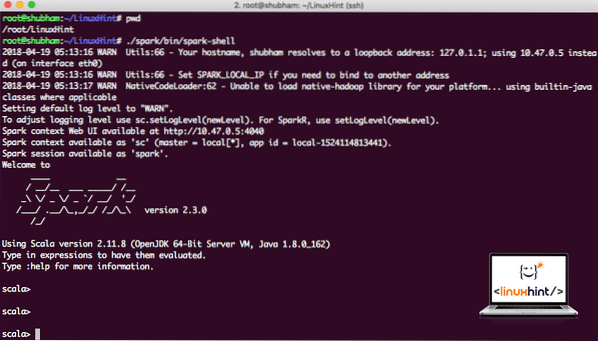
Запуск оболочки Spark
Мы видим в консоли, что Spark также открыл веб-консоль на порту 404. Давайте его посетим:
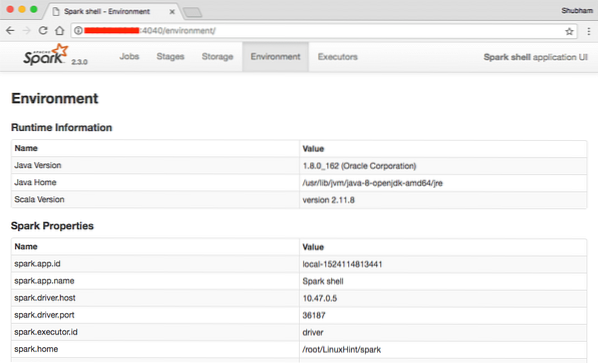
Веб-консоль Apache Spark
Хотя мы будем работать на самой консоли, веб-среда является важным местом, на которое следует обратить внимание при выполнении тяжелых заданий Spark, чтобы вы знали, что происходит в каждом выполняемом задании Spark.
Проверьте версию оболочки Spark с помощью простой команды:
sc.версияМы вернемся примерно так:
res0: String = 2.3.0Создание образца приложения Spark с помощью Scala
Теперь мы создадим образец приложения Word Counter с Apache Spark. Для этого сначала загрузите текстовый файл в Spark Context в оболочке Spark:
scala> var Data = sc.textFile ("/ root / LinuxHint / spark / README.мкр ")Данные: org.апач.Искра.rdd.RDD [String] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] в textFile по адресу: 24
scala>
Теперь текст, присутствующий в файле, должен быть разбит на токены, которыми может управлять Spark:
scala> var tokens = Данные.flatMap (s => s.расколоть(" "))токены: org.апач.Искра.rdd.RDD [String] = MapPartitionsRDD [2] в flatMap в: 25
scala>
Теперь инициализируйте счетчик каждого слова равным 1:
scala> var tokens_1 = токены.карта (s => (s, 1))tokens_1: org.апач.Искра.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] на карте по адресу: 25
scala>
Наконец, вычислите частоту каждого слова файла:
var sum_each = tokens_1.reduceByKey ((a, b) => a + b)Пора взглянуть на результат работы программы. Соберите жетоны и их количество:
scala> sum_each.собирать()res1: Array [(String, Int)] = Array ((package, 1), (For, 3), (Programs, 1), (processing.,1), (Потому что, 1), (The, 1), (page] (http: // spark.апач.org / документация.html).,1), (кластер.,1), (its, 1), ([run, 1), (than, 1), (APIs, 1), (have, 1), (Try, 1), (computation, 1), (through, 1 ), (несколько, 1), (Это, 2), (график, 1), (Улей, 2), (хранилище, 1), (["Указание, 1), (Кому, 2), (" пряжа " , 1), (Один раз, 1), (["Полезно, 1), (предпочитаю, 1), (SparkPi, 2), (движок, 1), (версия, 1), (файл, 1), (документация ,, 1), (обработка ,, 1), (the, 24), (are, 1), (системы.,1), (params, 1), (not, 1), (different, 1), (refer, 2), (Interactive, 2), (R ,, 1), (при условии.,1), (если, 4), (сборка, 4), (когда, 1), (быть, 2), (Тесты, 1), (Apache, 1), (поток, 1), (программы, 1 ), (в том числе, 4), (./ bin / run-example, 2), (Spark.,1), (упаковка.,1), (1000).count (), 1), (Версии, 1), (HDFS, 1), (D…
scala>
Отлично! Нам удалось запустить простой пример счетчика слов с использованием языка программирования Scala с текстовым файлом, уже присутствующим в системе.
Заключение
В этом уроке мы рассмотрели, как установить и начать использовать Apache Spark в Ubuntu 17.10 и также запустите на нем пример приложения.
Прочтите больше сообщений на основе Ubuntu здесь.


