Эта статья является продолжением предыдущей. Мы расскажем, как уточнить запрос, сформулировать более сложные критерии поиска с различными параметрами и понять различные веб-формы страницы запроса Apache Solr. Кроме того, мы обсудим, как постобработать результат поиска, используя различные форматы вывода, такие как XML, CSV и JSON.
Запрос Apache Solr
Apache Solr разработан как веб-приложение и служба, работающая в фоновом режиме. В результате любое клиентское приложение может взаимодействовать с Solr, отправляя ему запросы (в центре внимания этой статьи), манипулируя ядром документа путем добавления, обновления и удаления индексированных данных и оптимизации основных данных. Возможны два варианта - через панель управления / веб-интерфейс или через API, отправив соответствующий запрос.
Обычно используется первый вариант для тестирования, а не для обычного доступа. На рисунке ниже показана панель управления из пользовательского интерфейса администрирования Apache Solr с различными формами запросов в веб-браузере Firefox.
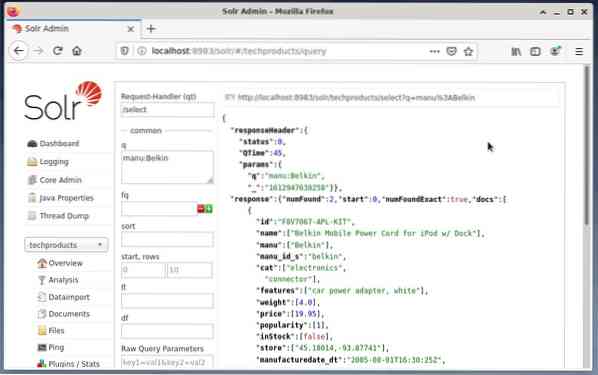
Сначала в меню под полем выбора ядра выберите пункт меню «Запрос». Затем на панели управления отобразятся следующие поля ввода:
- Обработчик запросов (qt):
Определите, какой тип запроса вы хотите отправить в Solr. Вы можете выбрать между обработчиками запросов по умолчанию «/ select» (запросить индексированные данные), «/ update» (обновить индексированные данные) и «/ delete» (удалить указанные индексированные данные) или самостоятельно определенным. - Событие запроса (q):
Определите, какие имена и значения полей нужно выбрать. - Фильтровать запросы (fq):
Ограничить расширенный набор документов, которые можно вернуть, не влияя на оценку документа. - Порядок сортировки (сортировка):
Определите порядок сортировки результатов запроса по возрастанию или убыванию - Окно вывода (начало и строки):
Ограничить вывод указанными элементами - Список полей (fl):
Ограничивает информацию, включенную в ответ на запрос, указанным списком полей. - Формат вывода (wt):
Определите желаемый формат вывода. Значение по умолчанию - JSON.
При нажатии на кнопку «Выполнить запрос» выполняется желаемый запрос. Практические примеры см. Ниже.
Как второй вариант, вы можете отправить запрос через API. Это HTTP-запрос, который может быть отправлен в Apache Solr любым приложением. Solr обрабатывает запрос и возвращает ответ. Особым случаем этого является подключение к Apache Solr через Java API. Это было передано на аутсорсинг отдельному проекту под названием SolrJ [7] - Java API без необходимости подключения HTTP.
Синтаксис запроса
Синтаксис запроса лучше всего описан в [3] и [5]. Различные имена параметров напрямую соответствуют именам полей ввода в формах, описанных выше. В таблице ниже они перечислены, а также приведены практические примеры.
Указатель параметров запроса
| Параметр | Описание | Пример |
|---|---|---|
| q | Основной параметр запроса Apache Solr - имена и значения полей. Их оценки сходства задокументированы с терминами в этом параметре. | Id: 5 автомобили: * Адилла * *: X5 |
| fq | Ограничьте набор результатов документами надмножества, которые соответствуют фильтру, например, определенному с помощью анализатора запросов диапазона функций | модель id, модель |
| Начало | Смещения для результатов страницы (начало). Значение этого параметра по умолчанию - 0. | 5 |
| ряды | Смещения для результатов страницы (конец). По умолчанию значение этого параметра - 10 | 15 |
| Сортировать | В нем указывается список полей, разделенных запятыми, по которым должны быть отсортированы результаты запроса | модель по возрастанию |
| эт | Он определяет список полей, возвращаемых для всех документов в наборе результатов | модель id, модель |
| вес | Этот параметр представляет тип автора ответа, который мы хотели бы просмотреть результат. Значение по умолчанию - JSON. | json xml |
Поиск выполняется через HTTP-запрос GET со строкой запроса в параметре q. Примеры ниже поясняют, как это работает. Используется curl для отправки запроса в Solr, установленный локально.
- Получить все наборы данных из ядра curl cars http: // localhost: 8983 / solr / cars / query?д = *: *
- Получить все наборы данных из основных автомобилей с идентификатором 5 curl http: // localhost: 8983 / solr / cars / query?q = id: 5
- Получить модель поля из всех наборов данных основных автомобилей
Вариант 1 (с экранированным символом &): завиток http: // localhost: 8983 / solr / cars / query?q = id: * \ & fl = модельВариант 2 (запрос одиночными галочками):
curl 'http: // localhost: 8983 / solr / cars / query?q = id: * & fl = модель ' - Получить все наборы данных об основных автомобилях, отсортированных по цене в порядке убывания, и вывести только поля марки, модели и цены (версия в отдельных отметках): curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
sort = цена по убыванию &
fl = марка, модель, цена ' - Получите первые пять наборов данных об основных автомобилях, отсортированных по цене в порядке убывания, и выведите только поля марки, модели и цены (версия в единичных тиках): curl http: // localhost: 8983 / solr / cars / query - d '
q = *: * &
row = 5 &
sort = цена по убыванию &
fl = марка, модель, цена ' - Получите первые пять наборов данных об основных автомобилях, отсортированных по цене в порядке убывания, и выведите только поля марки, модели и цены, а также их оценку релевантности (версия в отдельных отметках): curl http: // localhost: 8983 / solr / автомобили / запрос -d '
q = *: * &
row = 5 &
sort = цена по убыванию &
fl = марка, модель, цена, оценка ' - Вернуть все сохраненные поля, а также оценку релевантности: curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
fl = *, оценка '
Кроме того, вы можете определить свой собственный обработчик запросов для отправки дополнительных параметров запроса в синтаксический анализатор запросов, чтобы контролировать, какая информация возвращается.
Парсеры запросов
Apache Solr использует так называемый анализатор запросов - компонент, который переводит вашу строку поиска в конкретные инструкции для поисковой системы. Парсер запросов стоит между вами и документом, который вы ищете.
Solr поставляется с множеством типов парсеров, которые различаются способом обработки отправленного запроса. Стандартный синтаксический анализатор запросов хорошо работает для структурированных запросов, но менее устойчив к синтаксическим ошибкам. В то же время как DisMax, так и Extended DisMax Query Parser оптимизированы для запросов, подобных естественному языку. Они предназначены для обработки простых фраз, вводимых пользователями, и для поиска отдельных терминов в нескольких полях с использованием различных весов.
Кроме того, Solr также предлагает так называемые функциональные запросы, которые позволяют комбинировать функцию с запросом для получения определенной оценки релевантности. Эти парсеры называются «Анализатор запросов функций» и «Анализатор запросов диапазона функций». В приведенном ниже примере показано, что последний выбирает все наборы данных для «bmw» (хранящиеся в поле данных make) с моделями от 318 до 323:
curl http: // localhost: 8983 / solr / cars / query -d 'q = марка: bmw &
fq = модель: [318–323] '
Постобработка результатов
Отправка запросов в Apache Solr - это одна часть, а последующая обработка результатов поиска - другая. Во-первых, вы можете выбирать между различными форматами ответов - от JSON до XML, CSV и упрощенного формата Ruby. Просто укажите соответствующий параметр wt в запросе. В приведенном ниже примере кода показано, как получить набор данных в формате CSV для всех элементов с помощью curl с экранированным символом &:
завиток http: // localhost: 8983 / solr / cars / query?q = id: 5 \ & wt = csvРезультатом является следующий список, разделенный запятыми:

Чтобы получить результат в виде XML-данных, но только два выходных поля создают и модели, выполните следующий запрос:
завиток http: // localhost: 8983 / solr / cars / query?q = *: * \ & fl = make, model \ & wt = xmlВывод отличается и содержит как заголовок ответа, так и фактический ответ:
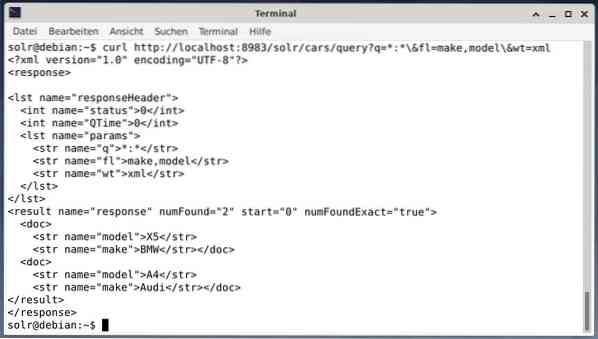
Wget просто выводит полученные данные на стандартный вывод. Это позволяет вам обработать ответ с помощью стандартных инструментов командной строки. Чтобы перечислить некоторые, он содержит jq [9] для JSON, xsltproc, xidel, xmlstarlet [10] для XML, а также csvkit [11] для формата CSV.
Заключение
В этой статье показаны различные способы отправки запросов в Apache Solr и объясняется, как обрабатывать результаты поиска. В следующей части вы узнаете, как использовать Apache Solr для поиска в PostgreSQL, системе управления реляционными базами данных.
Об авторах
Жаки Кабета - защитник окружающей среды, заядлый исследователь, тренер и наставник. В нескольких африканских странах она работала в ИТ-индустрии и в среде НПО.
Франк Хофманн - ИТ-разработчик, тренер и автор, предпочитающий работать из Берлина, Женевы и Кейптауна. Соавтор книги по управлению пакетами Debian, доступной на dpmb.org
Ссылки и ссылки
- [1] Apache Solr, https: // lucene.апач.org / solr /
- [2] Фрэнк Хофманн и Жаки Кабета: Введение в Apache Solr. Часть 1, http: // linuxhint.ком
- [3] Yonik Seelay: Синтаксис запросов Solr, http: // yonik.com / solr / синтаксис запроса /
- [4] Yonik Seelay: Solr Tutorial, http: // yonik.com / solr-tutorial /
- [5] Apache Solr: запрос данных, руководство, https: // www.учебная точка.com / apache_solr / apache_solr_querying_data.htm
- [6] Люцен, https: // люцен.апач.org /
- [7] SolrJ, https: // lucene.апач.org / solr / guide / 8_8 / using-solrj.html
- [8] завиток, https: // завиток.se /
- [9] jq, https: // github.com / stedolan / jq
- [10] xmlstarlet, http: // xmlstar.Sourceforge.сеть/
- [11] csvkit, https: // csvkit.читать.io / en / последний /


