- 1 для истины или
- 0 для ложного
Ключевое значение логистической регрессии:
- Независимые переменные не должны быть мультиколлинеарными; если есть какие-то отношения, то их должно быть очень мало.
- Набор данных для логистической регрессии должен быть достаточно большим, чтобы получить лучшие результаты.
- В наборе данных должны быть только те атрибуты, которые имеют некоторое значение.
- Независимые переменные должны соответствовать логарифмические шансы.
Чтобы построить модель логистическая регрессия, мы используем scikit-learn библиотека. Ниже представлен процесс логистической регрессии в Python:
- Импортируйте все необходимые пакеты для логистической регрессии и других библиотек.
- Загрузите набор данных.
- Понять независимые переменные набора данных и зависимые переменные.
- Разделите набор данных на обучающие и тестовые данные.
- Инициализировать модель логистической регрессии.
- Совместите модель с обучающим набором данных.
- Прогнозируйте модель, используя тестовые данные, и рассчитайте точность модели.
Проблема: Первые шаги - собрать набор данных, к которому мы хотим применить Логистическая регрессия. Набор данных, который мы собираемся использовать здесь, предназначен для набора данных приема в MS. В этом наборе данных есть четыре переменных, три из которых являются независимыми (GRE, GPA, work_experience), а одна - зависимой переменной (допущено). Этот набор данных покажет, получит ли кандидат зачисление в престижный университет на основе его среднего академического балла, GRE или work_experience.
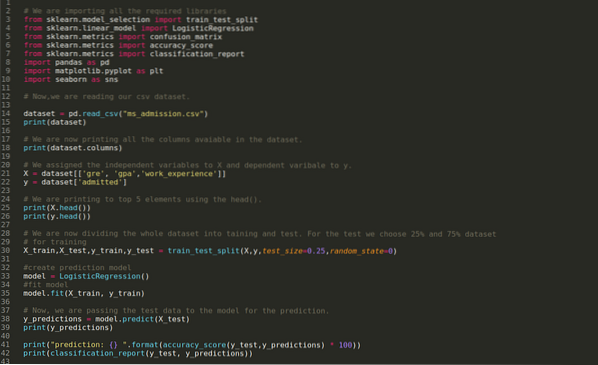
Шаг 1: Импортируем все необходимые библиотеки, которые нам нужны для программы python.
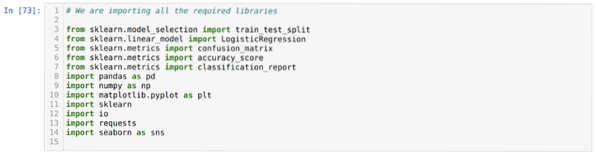
Шаг 2: Теперь мы загружаем наш набор данных допуска ms, используя функцию pandas read_csv.

Шаг 3: Набор данных выглядит следующим образом:
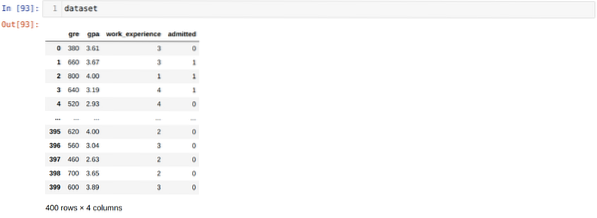
Шаг 4: Мы проверяем все столбцы, доступные в наборе данных, а затем устанавливаем все независимые переменные на переменную X и зависимые переменные на y, как показано на скриншоте ниже.

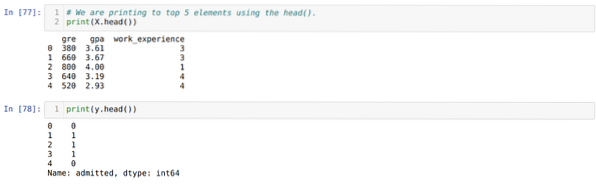
Шаг 5: После установки независимых переменных на X и зависимой переменной на y, теперь мы печатаем здесь, чтобы проверить X и y с помощью функции head pandas.
Шаг 6: Теперь мы собираемся разделить весь набор данных на обучение и тестирование. Для этого мы используем метод sklearn train_test_split. Мы отдали 25% всего набора данных тесту, а оставшиеся 75% набора данных - обучению.
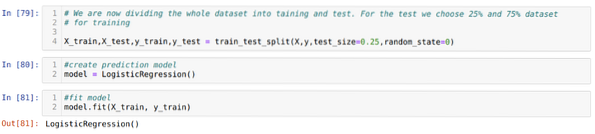
Шаг 7: Теперь мы собираемся разделить весь набор данных на обучение и тестирование. Для этого мы используем метод sklearn train_test_split. Мы отдали 25% всего набора данных тесту, а оставшиеся 75% набора данных - обучению.
Затем мы создаем модель логистической регрессии и подгоняем обучающие данные.
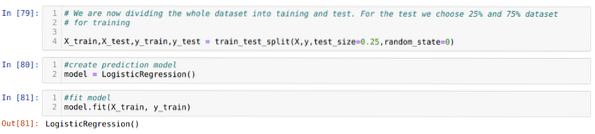
Шаг 8: Теперь наша модель готова для прогнозирования, поэтому мы передаем тестовые (X_test) данные в модель и получили результаты. Результаты показывают (y_predictions), что значения 1 (допущено) и 0 (не допущено).

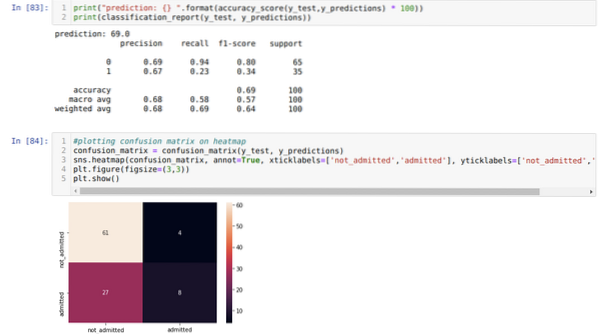
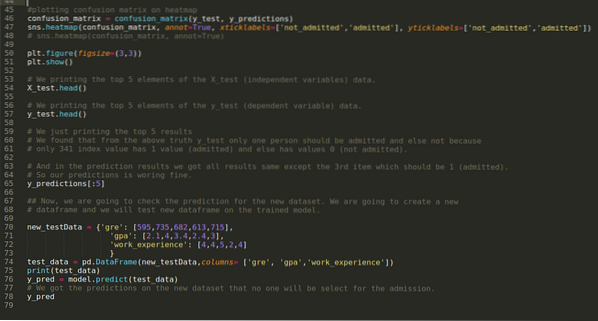
Шаг 9: Теперь распечатываем отчет о классификации и матрицу неточностей.
Классификационный_репорт показывает, что модель может предсказывать результаты с точностью до 69%.
Матрица неточностей показывает общие детали данных X_test как:
TP = истинные положительные результаты = 8
TN = True Negatives = 61
FP = ложные срабатывания = 4
FN = ложноотрицательные = 27
Итак, общая точность согласно confusion_matrix составляет:
Точность = (TP + TN) / Всего = (8 + 61) / 100 = 0.69
Шаг 10: Теперь мы собираемся перепроверить результат с помощью печати. Итак, мы просто печатаем верхние 5 элементов X_test и y_test (фактическое истинное значение), используя функцию head pandas. Затем мы также печатаем 5 лучших результатов прогнозов, как показано ниже:
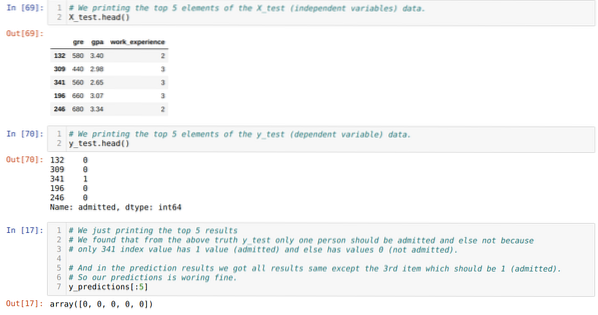
Мы объединяем все три результата в таблицу, чтобы понять прогнозы, как показано ниже. Мы видим, что за исключением 341 данных X_test, которые были истинными (1), прогноз неверен (0), иначе. Итак, прогнозы нашей модели работают на 69%, как мы уже показали выше.

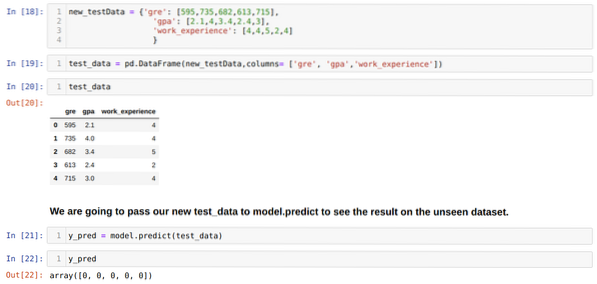
Шаг 11: Итак, мы понимаем, как прогнозы модели выполняются на невидимом наборе данных, таком как X_test. Итак, мы создали просто случайно новый набор данных с использованием фрейма данных pandas, передали его в обученную модель и получили результат, показанный ниже.
Полный код на Python приведен ниже:
Код этого блога вместе с набором данных доступен по следующей ссылке
https: // github.com / shekharpandey89 / logistic-regression


