pip установить BeautifulSoup4
Чтобы проверить успешность установки, активируйте интерактивную оболочку Python и импортируйте BeautifulSoup. Если ошибок нет, значит, все прошло нормально. Если вы не знаете, как это сделать, введите следующие команды в свой терминал.
$ питонPython 3.5.2 (по умолчанию, 14 сентября 2017 г., 22:51:06)
[GCC 5.4.0 20160609] в Linux
Введите «помощь», «авторские права», «кредиты» или «лицензия» для получения дополнительной информации.
>>> импорт bs4
Для работы с библиотекой BeautifulSoup необходимо передать html. При работе с реальными веб-сайтами вы можете получить html веб-страницы, используя библиотеку запросов. Установка и использование библиотеки запросов выходит за рамки этой статьи, однако вы можете найти свой путь в документации, которую довольно легко использовать. В этой статье мы просто будем использовать html в строке Python, которую мы будем называть html.
html = "" "[электронная почта защищена]
pparkerworks.ком
"" "
Чтобы использовать beautifulsoup, мы импортируем его в код, используя следующий код:
из bs4 импорт BeautifulSoupЭто введет BeautifulSoup в наше пространство имен, и мы сможем использовать его при синтаксическом анализе нашей строки.
soup = BeautifulSoup (html, "lxml")Сейчас, суп является объектом BeautifulSoup типа bs4.BeautifulSoup, и мы сможем выполнить все операции BeautifulSoup на супПеременная.
Давайте посмотрим, что мы можем делать с BeautifulSoup прямо сейчас.
СДЕЛАТЬ УЖЕСТВЕННОЕ, КРАСИВОЕ
Когда BeautifulSoup анализирует html, он обычно не в лучшем из форматов. Интервал довольно ужасный. Теги трудно найти. Вот изображение, чтобы показать, как они будут выглядеть, когда вы напечатаете суп:
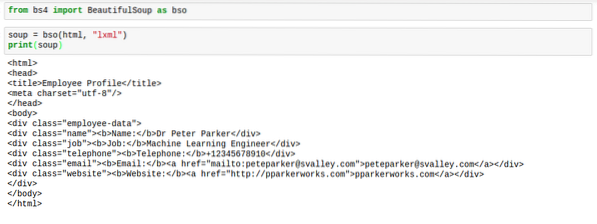
Однако есть решение этой проблемы. Решение дает html идеальный интервал, чтобы все выглядело хорошо. Это решение заслуженно называют «украсить«.
По общему признанию, вы можете не использовать эту функцию большую часть времени; однако бывают случаи, когда у вас может не быть доступа к инструменту проверки элементов в веб-браузере. В те времена ограниченных ресурсов вы найдете метод prettify очень полезным.
Вот как вы его используете:
суп.prettify ()Разметка будет выглядеть правильно, как на изображении ниже:
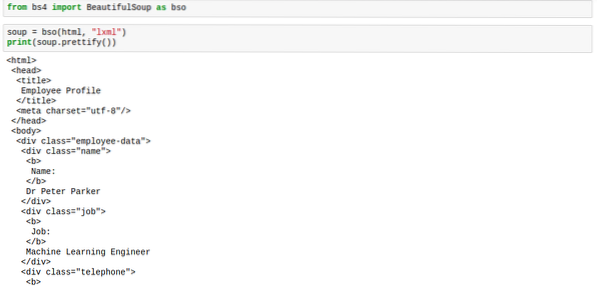
Когда вы применяете метод prettify к супу, результат больше не тип bs4.BeautifulSoup. В результате теперь введите unicode. Это означает, что вы не можете применять к нему другие методы BeautifulSoup, однако сам суп не затронут, поэтому мы в безопасности.
НАЙТИ НАШИ ЛЮБИМЫЕ ТЕГИ
HTML состоит из тегов. Он хранит в них все свои данные, и среди всего этого беспорядка лежат данные, которые нам нужны. По сути, это означает, что когда мы находим правильные теги, мы можем получить то, что нам нужно.
Итак, как нам найти правильные теги? Мы используем методы find и find_all от BeautifulSoup.
Вот как они работают:
В найти метод ищет первый тег с нужным именем и возвращает объект типа bs4.элемент.Тег.
В найти все с другой стороны, ищет все теги с нужным именем тега и возвращает их в виде списка типа bs4.элемент.ResultSet. Все элементы в списке относятся к типу bs4.элемент.Отметьте тег, чтобы мы могли выполнить индексацию по списку и продолжить исследование beautifulsoup.
Посмотрим код. Найдем все теги div:
суп.найти («div»)Получим следующий результат:
Проверив переменную html, вы заметите, что это первый тег div.
суп.find_all («div»)Получим следующий результат:
[[электронная почта защищена]
pparkerworks.ком
Он возвращает список. Если, например, вам нужен третий тег div, вы запустите следующий код:
суп.find_all («div») [2]Он вернет следующее:
ПОИСК АТРИБУТОВ НАШИХ ЛЮБИМЫХ ТЕГОВ
Теперь, когда мы увидели, как получить наши любимые теги, как насчет получения их атрибутов??
В этот момент вы можете подумать: «Зачем нам нужны атрибуты для?«. Что ж, в большинстве случаев большая часть необходимых данных - это адреса электронной почты и веб-сайты. На такие данные обычно есть гиперссылки на веб-страницах, причем ссылки указаны в атрибуте «href».
Когда мы извлекли нужный тег с помощью методов find или find_all, мы можем получить атрибуты, применив attrs. Это вернет словарь атрибута и его значение.
Например, чтобы получить атрибут электронной почты, мы получаем теги, которые окружают необходимую информацию, и делают следующее.
суп.find_all («а») [0].attrsЧто вернет следующий результат:
'href': 'mailto: [адрес электронной почты защищен]'То же самое и с атрибутом сайта.
суп.find_all («а») [1].attrsЧто вернет следующий результат:
'href': 'http: // pparkerworks.ком'Возвращаемые значения являются словарями, и для получения ключей и значений можно применить обычный синтаксис словаря.
ПОСМОТРЕТЬ РОДИТЕЛЯ И ДЕТЕЙ
Везде есть теги. Иногда нам нужно знать, что такое дочерние теги и что это за родительский тег.
Если вы еще не знаете, что такое родительский и дочерний теги, этого краткого объяснения должно хватить: родительский тег является непосредственным внешним тегом, а дочерний - непосредственным внутренним тегом рассматриваемого тега.
Взглянув на наш html, тег body является родительским тегом всех тегов div. Кроме того, полужирный тег и тег привязки являются дочерними элементами тегов div, где это применимо, поскольку не все теги div имеют теги привязки.
Таким образом, мы можем получить доступ к родительскому тегу, вызвав findParent метод.
суп.найти ("div").findParent ()Это вернет весь тег body:
[электронная почта защищена]
pparkerworks.ком
Чтобы получить дочерний тег четвертого тега div, мы вызываем findChildren метод:
суп.find_all ("div") [4].findChildren ()Он возвращает следующее:
[Веб-сайт:, pparkerworks.ком]ЧТО В ЭТОМ ДЛЯ НАС?
При просмотре веб-страниц мы не видим теги везде на экране. Все, что мы видим, - это содержание разных тегов. Что, если нам нужно содержимое тега без всех угловых скобок, делающих жизнь неудобной?? Это не сложно, все, что нам нужно сделать, это позвонить get_text в выбранном теге, и мы получаем текст в теге, и если в теге есть другие теги, он также получает их текстовые значения.
Вот пример:
суп.найти ("тело").get_text ()Это возвращает все текстовые значения в теге body:
Имя: Д-р Питер ПаркерРабота: инженер по машинному обучению
Телефон: +12345678910
Электронная почта: [электронная почта защищена]
Сайт: pparkerworks.ком
ЗАКЛЮЧЕНИЕ
Вот что у нас есть для этой статьи. Однако есть и другие интересные вещи, которые можно сделать с beautifulsoup. Вы можете либо проверить документацию, либо использовать реж (BeautfulSoup) в интерактивной оболочке, чтобы просмотреть список операций, которые можно выполнять с объектом BeautifulSoup. Это все от меня сегодня, пока я снова не напишу.