Всякий раз, когда мы хотим интегрировать брокеры сообщений в наше приложение, что позволяет нам легко масштабировать и асинхронно подключать нашу систему, существует множество брокеров сообщений, которые могут составить список, из которого вы можете выбрать один, например:
- RabbitMQ
- Апач Кафка
- ActiveMQ
- AWS SQS
- Redis
У каждого из этих брокеров сообщений есть свой список плюсов и минусов, но наиболее сложными вариантами являются первые два, RabbitMQ и Apache Kafka. В этом уроке мы перечислим моменты, которые могут помочь сузить выбор одного предпочтения другому. Наконец, стоит отметить, что ни один из них не лучше другого во всех случаях использования, и это полностью зависит от того, чего вы хотите достичь, поэтому нет единственного правильного ответа!
Мы начнем с простого знакомства с этими инструментами.
Апач Кафка
Как мы уже говорили в этом уроке, Apache Kafka - это распределенный, отказоустойчивый, горизонтально масштабируемый журнал фиксации. Это означает, что Kafka может очень хорошо выполнять термин «разделяй и управляй», он может реплицировать ваши данные для обеспечения доступности и обладает высокой масштабируемостью в том смысле, что вы можете включать новые серверы во время выполнения, чтобы увеличить его способность управлять большим количеством сообщений.
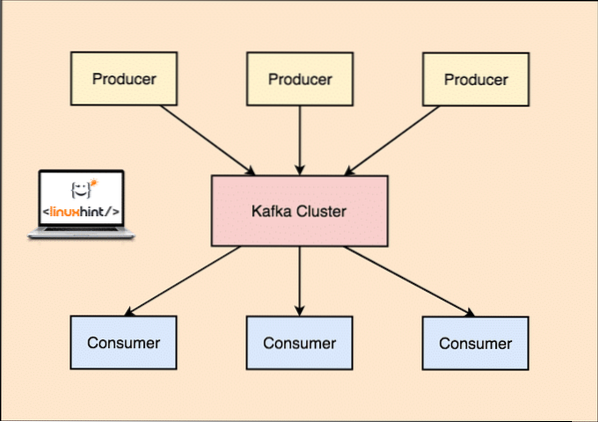
Kafka Производитель и Потребитель
RabbitMQ
RabbitMQ - это более универсальный и простой в использовании брокер сообщений, который сам ведет запись о том, какие сообщения были получены клиентом, и сохраняет другое. Даже если по какой-то причине сервер RabbitMQ выходит из строя, вы можете быть уверены, что сообщения, которые в настоящее время находятся в очередях, были сохранены в файловой системе, так что, когда RabbitMQ снова вернется, эти сообщения могут обрабатываться потребителями согласованным образом.
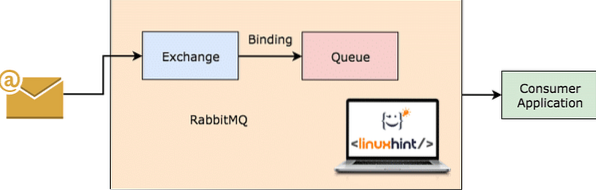
RabbitMQ работает
Сверхдержава: Apache Kafka
Основная сверхспособность Kafka заключается в том, что его можно использовать в качестве системы очередей, но это не то, что ограничивается. Кафка больше похож на круговой буфер который может масштабироваться до размера диска на машине в кластере и, таким образом, позволяет нам повторно читать сообщения. Это может быть сделано клиентом без необходимости зависеть от кластера Kafka, поскольку клиент полностью обязан отметить метаданные сообщения, которые он в настоящее время читает, и он может повторно посетить Kafka позже через указанный интервал, чтобы снова прочитать то же сообщение.
Обратите внимание, что время, в течение которого это сообщение может быть перечитано, ограничено и может быть настроено в конфигурации Kafka. Итак, как только это время закончится, клиент больше не сможет прочитать старое сообщение.
Суперсила: RabbitMQ
Основная сверхспособность RabbitMQ заключается в том, что он просто масштабируется, представляет собой высокопроизводительную систему очередей, которая имеет очень четко определенные правила согласованности и способность создавать множество типов моделей обмена сообщениями. Например, в RabbitMQ можно создать три типа обмена:
- Прямой обмен: обмен темами один на один
- Обмен темами: A тема определяется, на котором различные производители могут публиковать сообщение, а различные потребители могут связывать себя для прослушивания по этой теме, поэтому каждый из них получает сообщение, которое отправляется в эту тему.
- Обмен Fanout: это более строгий, чем обмен темами, так как когда сообщение публикуется в обмене fanout, все потребители, которые подключены к очередям, которые связываются с обменом fanout, получат сообщение.
Уже заметил разницу между RabbitMQ и Kafka? Разница в том, что если потребитель не подключен к обмену фэнаутом в RabbitMQ, когда сообщение было опубликовано, оно будет потеряно, потому что другие потребители использовали сообщение, но этого не происходит в Apache Kafka, поскольку любой потребитель может прочитать любое сообщение. в виде они поддерживают свой собственный курсор.
RabbitMQ ориентирован на брокера
Хороший брокер - это тот, кто гарантирует работу, которую он берет на себя, и в этом RabbitMQ хорош. Он наклонен в сторону гарантии доставки между производителями и потребителями, причем временные сообщения предпочтительнее долговечных.
RabbitMQ использует самого брокера для управления состоянием сообщения и обеспечения доставки каждого сообщения каждому уполномоченному потребителю.
RabbitMQ предполагает, что потребители в основном онлайн.
Kafka ориентирован на производителя
Apache Kafka ориентирован на производителя, поскольку он полностью основан на разделении и потоке пакетов событий, содержащих данные, и их преобразовании в надежных брокеров сообщений с помощью курсоров, поддержки пакетных потребителей, которые могут быть в автономном режиме, или онлайн-потребителей, которым нужны сообщения с низкой задержкой.
Kafka гарантирует, что сообщение остается безопасным до определенного периода времени, реплицируя сообщение на свои узлы в кластере и поддерживая согласованное состояние.
Итак, Кафка не предполагают, что кто-то из его потребителей в основном в сети, и ему все равно.
Заказ сообщений
С RabbitMQ порядок публикаций управляется последовательно и потребители получат сообщение в самом опубликованном порядке. С другой стороны, Kafka не делает этого, поскольку предполагает, что опубликованные сообщения имеют тяжелый характер, поэтому потребители работают медленно и могут отправлять сообщения в любом порядке, поэтому он также не управляет порядком самостоятельно. Хотя мы можем настроить аналогичную топологию для управления порядком в Kafka, используя последовательный обмен хешами или плагин шардинга., или даже больше видов топологий.
Полная задача, которой управляет Apache Kafka, состоит в том, чтобы действовать как «амортизатор» между непрерывным потоком событий и потребителями, из которых одни находятся в сети, а другие могут быть отключены - только пакетное потребление на ежечасной или даже ежедневной основе.
Заключение
В этом уроке мы изучили основные различия (а также сходства) между Apache Kafka и RabbitMQ. В некоторых средах оба показали исключительную производительность, например, RabbitMQ потребляет миллионы сообщений в секунду, а Kafka потребляет несколько миллионов сообщений в секунду. Основное архитектурное отличие состоит в том, что RabbitMQ управляет своими сообщениями почти в памяти и поэтому использует большой кластер (30+ узлов), тогда как Kafka фактически использует возможности последовательных операций дискового ввода-вывода и требует меньше оборудования.
Опять же, использование каждого из них по-прежнему полностью зависит от варианта использования в приложении. Счастливого обмена сообщениями !


