Apache Hadoop - это решение для больших данных для хранения и анализа больших объемов данных. В этой статье мы подробно расскажем о сложных этапах настройки Apache Hadoop, чтобы вы могли как можно быстрее приступить к работе с ним в Ubuntu. В этом посте мы установим Apache Hadoop на Ubuntu 17.10 машина.
Версия Ubuntu
В этом руководстве мы будем использовать Ubuntu версии 17.10 (GNU / Linux 4.13.0-38-общий x86_64).
Обновление существующих пакетов
Чтобы начать установку Hadoop, необходимо обновить наш компьютер с помощью последних доступных пакетов программного обеспечения. Мы можем сделать это с помощью:
sudo apt-get update && sudo apt-get -y dist-upgradeПоскольку Hadoop основан на Java, нам необходимо установить его на нашу машину. Мы можем использовать любую версию Java выше Java 6. Здесь мы будем использовать Java 8:
sudo apt-get -y установить openjdk-8-jdk-headlessСкачивание файлов Hadoop
Все необходимые пакеты теперь существуют на нашей машине. Мы готовы загрузить необходимые файлы Hadoop TAR, чтобы начать их настройку и запустить образец программы с Hadoop.
В этом руководстве мы будем устанавливать Hadoop v3.0.1. Загрузите соответствующие файлы с помощью этой команды:
wget http: // зеркало.cc.Колумбия.edu / pub / программное обеспечение / apache / hadoop / общий / hadoop-3.0.1 / hadoop-3.0.1.деготь.gzВ зависимости от скорости сети это может занять до нескольких минут, так как файл большой по размеру:
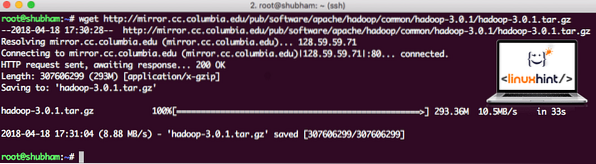
Скачивание Hadoop
Найдите последние бинарные файлы Hadoop здесь. Теперь, когда у нас есть загруженный файл TAR, мы можем извлечь его в текущий каталог:
tar xvzf hadoop-3.0.1.деготь.gzЭто займет несколько секунд из-за большого размера файла архива:
Hadoop в разархивированном виде
Добавлена новая группа пользователей Hadoop
Поскольку Hadoop работает через HDFS, новая файловая система также может нарушить работу нашей собственной файловой системы на машине Ubuntu. Чтобы избежать этого столкновения, мы создадим полностью отдельную группу пользователей и назначим ее Hadoop, чтобы она содержала свои собственные разрешения. Мы можем добавить новую группу пользователей с помощью этой команды:
addgroup hadoopМы увидим что-то вроде:
Добавление группы пользователей Hadoop
Мы готовы добавить в эту группу нового пользователя:
useradd -G hadoop hadoopuserОбратите внимание, что все команды, которые мы запускаем, выполняются от имени пользователя root. С помощью команды aove мы смогли добавить нового пользователя в созданную нами группу.
Чтобы позволить пользователю Hadoop выполнять операции, нам также необходимо предоставить ему root-доступ. Открой / и т.д. / sudoers файл с помощью этой команды:
sudo visudoПрежде чем мы что-нибудь добавим, файл будет выглядеть так:
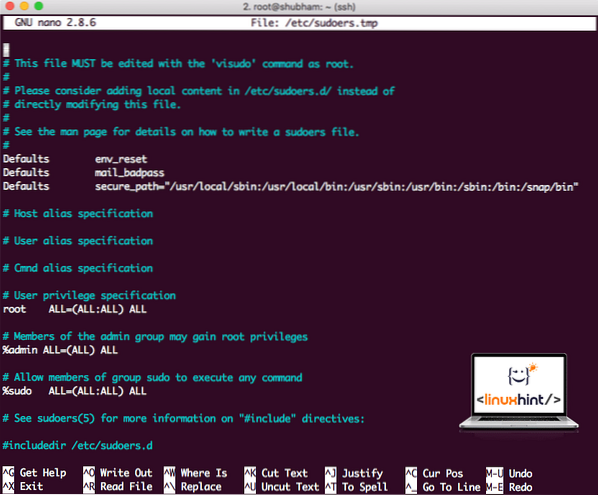
Файл Sudoers перед добавлением чего-либо
Добавьте в конец файла следующую строку:
hadoopuser ALL = (ВСЕ) ВСЕТеперь файл будет выглядеть так:
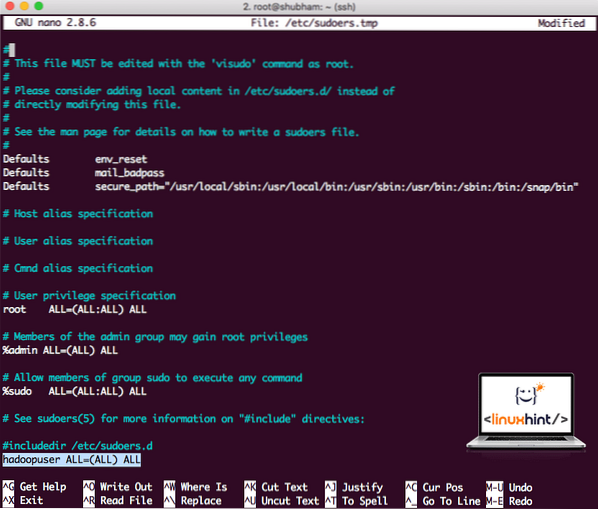
Файл Sudoers после добавления пользователя Hadoop
Это была основная установка для предоставления Hadoop платформы для выполнения действий. Теперь мы готовы настроить одноузловой кластер Hadoop.
Настройка одного узла Hadoop: автономный режим
Когда дело доходит до реальной мощности Hadoop, его обычно настраивают на нескольких серверах, чтобы можно было масштабировать поверх большого количества наборов данных, присутствующих в Распределенная файловая система Hadoop (HDFS). Обычно это нормально для сред отладки и не используется для производственного использования. Чтобы упростить процесс, мы объясним, как мы можем выполнить настройку одного узла для Hadoop здесь.
Когда мы закончим установку Hadoop, мы также запустим образец приложения на Hadoop. На данный момент файл Hadoop называется hadoop-3.0.1. давайте переименуем его в hadoop для упрощения использования:
мв hadoop-3.0.1 хадупТеперь файл выглядит так:
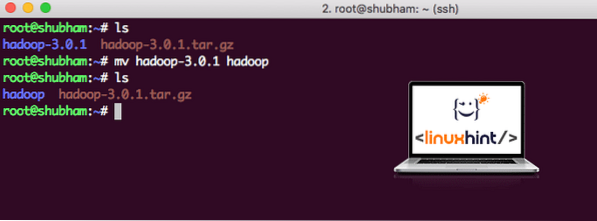
Перемещение Hadoop
Пришло время использовать созданного нами ранее пользователя hadoop и назначить право собственности на этот файл этому пользователю:
chown -R hadoopuser: хадуп / корень / хадупЛучшим местом для Hadoop будет каталог / usr / local /, поэтому переместим его туда:
мв hadoop / usr / местные /cd / usr / local /
Добавление Hadoop в путь
Чтобы выполнить скрипт Hadoop, мы добавим его в путь сейчас. Для этого откройте файл bashrc:
vi ~ /.bashrcДобавьте эти строки в конец .bashrc, чтобы путь мог содержать путь к исполняемому файлу Hadoop:
# Настроить Hadoop и Java Homeэкспорт HADOOP_HOME = / usr / local / hadoop
экспорт JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64
экспорт ПУТЬ = $ ПУТЬ: $ HADOOP_HOME / bin
Файл выглядит так:
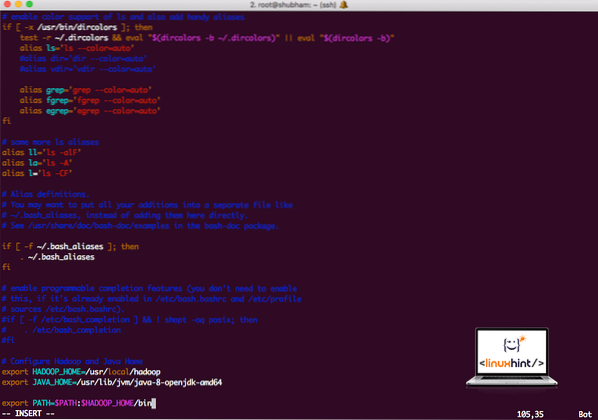
Добавление Hadoop в путь
Поскольку Hadoop использует Java, нам нужно сообщить файлу среды Hadoop Hadoop-env.ш где он расположен. Расположение этого файла может различаться в зависимости от версии Hadoop. Чтобы легко найти, где находится этот файл, выполните следующую команду прямо вне каталога Hadoop:
найти hadoop / -name hadoop-env.шМы получим вывод для расположения файла:
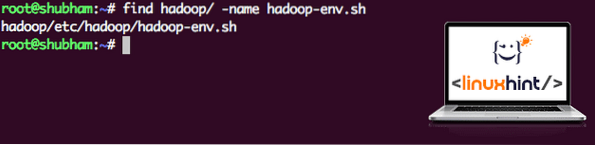
Расположение файла среды
Давайте отредактируем этот файл, чтобы сообщить Hadoop о местонахождении Java JDK, вставим его в последнюю строку файла и сохраним:
экспорт JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64На этом установка и настройка Hadoop завершены. Теперь мы готовы запустить наш образец приложения. Но подождите, мы никогда не делали образец приложения!
Запуск образца приложения с Hadoop
Фактически, установка Hadoop поставляется со встроенным образцом приложения, которое готово к запуску, как только мы закончим установку Hadoop. Звучит хорошо, правда?
Выполните следующую команду, чтобы запустить пример JAR:
банка hadoop / корень / hadoop / share / hadoop / mapreduce / hadoop-mapreduce-examples-3.0.1.jar wordcount / корень / hadoop / README.txt / root / ВыводHadoop покажет, сколько обработки было выполнено на узле:
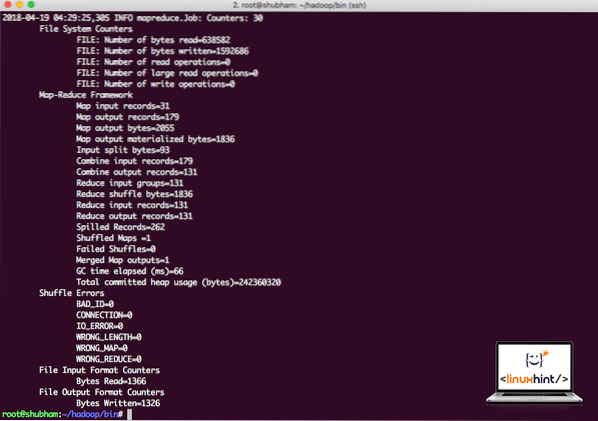
Статистика обработки Hadoop
Как только вы выполните следующую команду, мы увидим файл part-r-00000 как результат. Давайте посмотрим на содержимое вывода:
кот part-r-00000Вы получите что-то вроде:
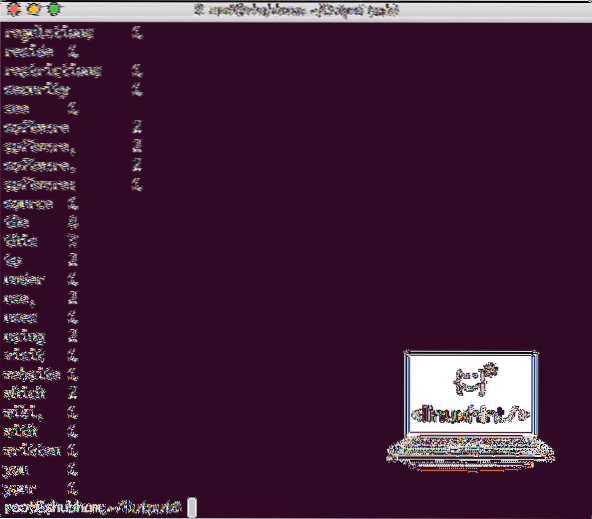
Вывод количества слов с помощью Hadoop
Заключение
В этом уроке мы рассмотрели, как установить и начать использовать Apache Hadoop в Ubuntu 17.10 машина. Hadoop отлично подходит для хранения и анализа огромного количества данных, и я надеюсь, что эта статья поможет вам быстро начать использовать его в Ubuntu.


