
Когда я начал работать с проблемами машинного обучения, то запаниковал, какой алгоритм мне использовать? Или какой из них легко применить? Если вы похожи на меня, то эта статья может помочь вам узнать об алгоритмах, методах или методах искусственного интеллекта и машинного обучения для решения любых неожиданных или даже ожидаемых проблем.
Машинное обучение - это такой мощный метод искусственного интеллекта, который может эффективно выполнять задачу без использования каких-либо явных инструкций. Модель машинного обучения может учиться на своих данных и опыте. Приложения машинного обучения автоматические, надежные и динамичные. Для решения этой динамической природы реальных проблем разработано несколько алгоритмов. В целом, существует три типа алгоритмов машинного обучения, таких как обучение с учителем, обучение без учителя и обучение с подкреплением.
Лучшие алгоритмы искусственного интеллекта и машинного обучения
Выбор подходящей техники или метода машинного обучения - одна из основных задач при разработке проекта искусственного интеллекта или машинного обучения. Потому что доступно несколько алгоритмов, и все они имеют свои преимущества и полезность. Ниже мы рассказываем 20 алгоритмов машинного обучения как для новичков, так и для профессионалов. Итак, давайте посмотрим.
1. Наивный байесовский
Наивный байесовский классификатор - это вероятностный классификатор, основанный на теореме Байеса с предположением независимости между признаками. Эти функции различаются от приложения к приложению. Это один из удобных методов машинного обучения для начинающих.
Наивный Байес - модель условной вероятности. Дан классифицируемый экземпляр проблемы, представленный вектором Икс знак равноИкся … Иксп) представляя некоторые n характеристик (независимых переменных), он присваивает текущим экземплярам вероятности для каждого из K потенциальных результатов:
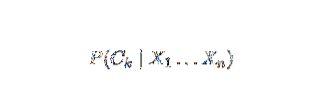 Проблема с приведенной выше формулировкой заключается в том, что если количество признаков n является значительным или если элемент может принимать большое количество значений, то основывать такую модель на таблицах вероятности невозможно. Поэтому мы переделываем модель, чтобы сделать ее более управляемой. Используя теорему Байеса, условную вероятность можно записать как,
Проблема с приведенной выше формулировкой заключается в том, что если количество признаков n является значительным или если элемент может принимать большое количество значений, то основывать такую модель на таблицах вероятности невозможно. Поэтому мы переделываем модель, чтобы сделать ее более управляемой. Используя теорему Байеса, условную вероятность можно записать как,
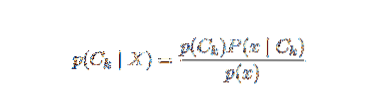
Используя терминологию байесовской вероятности, приведенное выше уравнение можно записать как:
Этот алгоритм искусственного интеллекта используется в классификации текста, я.е., анализ настроений, категоризация документов, фильтрация спама и классификация новостей. Этот метод машинного обучения хорошо работает, если входные данные разделены на заранее определенные группы. Кроме того, для этого требуется меньше данных, чем для логистической регрессии. Он превосходит в различных областях.
2. Машина опорных векторов
Машина опорных векторов (SVM) - один из наиболее широко используемых алгоритмов контролируемого машинного обучения в области классификации текста. Этот метод также используется для регрессии. Его также можно назвать сетями опорных векторов. Cortes & Vapnik разработали этот метод бинарной классификации. Модель контролируемого обучения - это подход машинного обучения, который выводит результат из помеченных данных обучения.
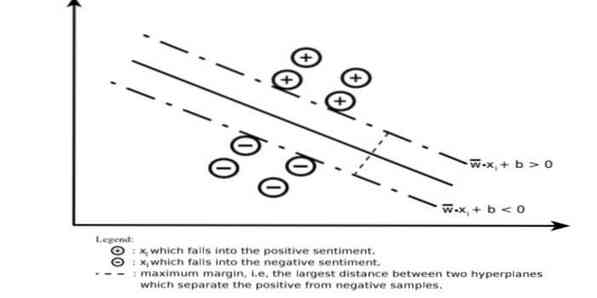
Машина опорных векторов строит гиперплоскость или набор гиперплоскостей в очень большой или бесконечномерной области. Он вычисляет линейную разделительную поверхность с максимальным запасом для данного обучающего набора.
Только подмножество входных векторов будет влиять на выбор поля (обведено на рисунке); такие векторы называются опорными векторами. Когда линейная разделительная поверхность не существует, например, при наличии зашумленных данных, подходят алгоритмы SVM с переменной запаса хода. Этот классификатор пытается разделить пространство данных с использованием линейных или нелинейных разграничений между различными классами.
SVM широко используется в задачах классификации образов и нелинейной регрессии. Кроме того, это один из лучших методов автоматической категоризации текста. Лучшее в этом алгоритме - то, что он не делает каких-либо серьезных предположений относительно данных.
Для реализации Support Vector Machine: библиотеки Data Science в Python - SciKit Learn, PyML, SVMStruct Библиотеки Python, LIBSVM и Data Science в R-Klar, e1071.
3. Линейная регрессия
Линейная регрессия - это прямой подход, который используется для моделирования взаимосвязи между зависимой переменной и одной или несколькими независимыми переменными. Если есть одна независимая переменная, то она называется простой линейной регрессией. Если доступно более одной независимой переменной, это называется множественной линейной регрессией.
Эта формула используется для оценки реальных значений, таких как цена домов, количество звонков, общий объем продаж, на основе непрерывных переменных. Здесь связь между независимыми и зависимыми переменными устанавливается путем подбора наилучшей линии. Эта линия наилучшего соответствия известна как линия регрессии и представлена линейным уравнением
Y = а * Х + Ь.
здесь,
- Y - зависимая переменная
- а - наклон
- X - независимая переменная
- б - перехват
Этот метод машинного обучения прост в использовании. Он выполняется быстро. Это можно использовать в бизнесе для прогнозирования продаж. Его также можно использовать при оценке рисков.
4. Логистическая регрессия
Вот еще один алгоритм машинного обучения - логистическая регрессия или логит-регрессия, который используется для оценки дискретных значений (двоичные значения, такие как 0/1, да / нет, истина / ложь) на основе заданного набора независимой переменной. Задача этого алгоритма - предсказать вероятность инцидента путем подбора данных к логит-функции. Его выходные значения лежат между 0 и 1.
Формула может использоваться в различных областях, таких как машинное обучение, научная дисциплина и медицина. Его можно использовать для прогнозирования опасности возникновения данного заболевания на основе наблюдаемых характеристик пациента. Логистическая регрессия может использоваться для прогнозирования желания клиента купить продукт. Этот метод машинного обучения используется в прогнозировании погоды, чтобы предсказать вероятность дождя.
Логистическую регрессию можно разделить на три типа -
- Бинарная логистическая регрессия
- Мульти-номинальная логистическая регрессия
- Порядковая логистическая регрессия
Логистическая регрессия менее сложна. Кроме того, он прочный. Он может обрабатывать нелинейные эффекты. Однако, если обучающие данные разрежены и имеют большие размеры, этот алгоритм машинного обучения может. Он не может предсказывать постоянные результаты.
5. K-ближайший-сосед (KNN)
Метод K-ближайшего соседа (kNN) - это хорошо известный статистический подход к классификации, который широко изучался на протяжении многих лет и рано применялся для задач категоризации. Он действует как непараметрическая методология для задач классификации и регрессии.
Этот метод AI и ML довольно прост. Он определяет категорию тестового документа t на основе голосования набора из k документов, ближайших к t с точки зрения расстояния, обычно евклидова расстояния. Основное правило принятия решения с учетом испытательного документа t для классификатора kNN:
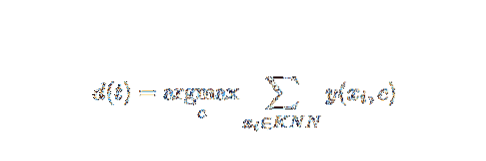
Где y (xi, c) - функция двоичной классификации для обучающего документа xi (которая возвращает значение 1, если xi помечено c, или 0 в противном случае), это правило помечает t с категорией, получившей наибольшее количество голосов в k. -ближайший район.
Мы можем сопоставить KNN с нашей реальной жизнью. Например, если вы хотите узнать несколько человек, о которых у вас нет информации, вы, возможно, предпочтете принять решение относительно его близких друзей и, следовательно, кругов, в которых он движется, и получить доступ к его / ее информации. Этот алгоритм требует больших вычислительных ресурсов.
6. K-означает
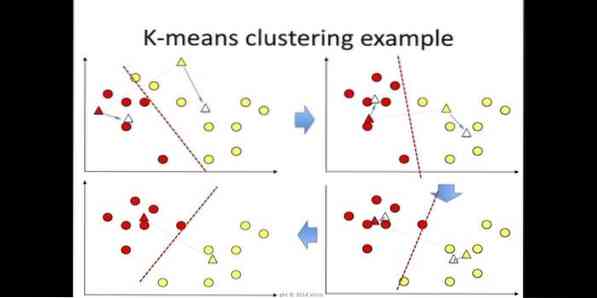
Кластеризация k-средних - это метод обучения без учителя, доступный для кластерного анализа при интеллектуальном анализе данных. Цель этого алгоритма - разделить n наблюдений на k кластеров, где каждое наблюдение принадлежит ближайшему среднему значению кластера. Этот алгоритм используется в сегментации рынка, компьютерном зрении и астрономии среди многих других областей.
7. Древо решений
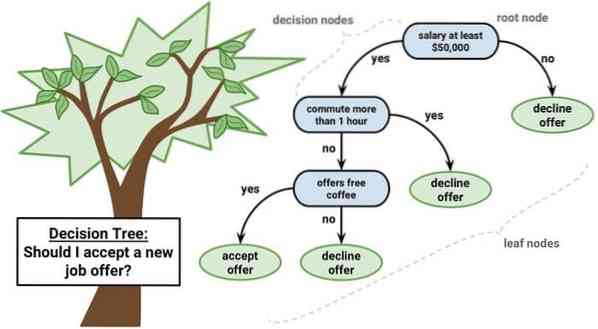
Дерево решений - это инструмент поддержки принятия решений, использующий графическое представление, т.е.е., древовидный граф или модель решений. Он обычно используется при анализе решений, а также является популярным инструментом в машинном обучении. Деревья решений используются в исследованиях и управлении операциями.
Он имеет структуру, подобную блок-схеме, в которой каждый внутренний узел представляет «тест» для атрибута, каждая ветвь представляет результат теста, а каждый листовой узел представляет метку класса. Маршрут от корня к листу известен как правила классификации. Он состоит из узлов трех типов:
- Узлы принятия решения: обычно представлены квадратами,
- Узлы вероятности: обычно представлены кружками,
- Конечные узлы: обычно представлены треугольниками.
Дерево решений просто для понимания и интерпретации. Он использует модель белого ящика. Кроме того, его можно комбинировать с другими методами принятия решений.
8. Случайный лес
Случайный лес - это популярный метод ансамблевого обучения, который работает путем построения множества деревьев решений во время обучения и вывода категории, которая является режимом категорий (классификация) или средним прогнозом (регрессия) каждого дерева.
Этот алгоритм машинного обучения работает быстро, и он может работать с несбалансированными и отсутствующими данными. Однако, когда мы использовали его для регрессии, он не может предсказать, выходящий за пределы диапазона обучающих данных, и может превосходить данные.
9. КОРЗИНА
Дерево классификации и регрессии (CART) - это один из видов дерева решений. Дерево решений работает как подход рекурсивного разделения, и CART делит каждый из входных узлов на два дочерних узла. На каждом уровне дерева решений алгоритм определяет условие - какую переменную и уровень следует использовать для разделения входного узла на два дочерних узла.
Шаги алгоритма CART приведены ниже:
- Взять входные данные
- Лучший сплит
- Лучшая переменная
- Разделите входные данные на левый и правый узлы
- Продолжить шаг 2-4
- Обрезка дерева решений
10. Алгоритм машинного обучения априори

Алгоритм Априори - это алгоритм категоризации. Этот метод машинного обучения используется для сортировки больших объемов данных. Его также можно использовать для отслеживания развития отношений и построения категорий. Этот алгоритм представляет собой метод обучения без учителя, который генерирует правила ассоциации из заданного набора данных.
Алгоритм машинного обучения Apriori работает как:
- Если набор элементов встречается часто, то часто встречаются и все подмножества набора элементов.
- Если набор элементов встречается нечасто, то все надмножества набора элементов также встречаются нечасто.
Этот алгоритм машинного обучения используется в различных приложениях, таких как обнаружение побочных реакций на лекарства, анализ корзины и автозаполнение приложений. Легко реализовать.
11. Анализ главных компонентов (PCA)
Анализ главных компонентов (PCA) - это неконтролируемый алгоритм. Новые функции ортогональны, что означает, что они не коррелированы. Перед выполнением PCA вы всегда должны нормализовать свой набор данных, потому что преобразование зависит от масштаба. Если вы этого не сделаете, функции, которые имеют наибольшее значение, будут доминировать над новыми основными компонентами.
PCA - универсальный метод. Этот алгоритм несложен и прост в реализации. Может использоваться при обработке изображений.
12. CatBoost
CatBoost - это алгоритм машинного обучения с открытым кодом от Яндекса. Название «CatBoost» происходит от двух слов «Категория» и «Повышение качества».'Он может сочетаться с фреймворками глубокого обучения, я.е., TensorFlow от Google и Core ML от Apple. CatBoost может работать с многочисленными типами данных для решения нескольких проблем.
13. Итерационный дихотомайзер 3 (ID3)
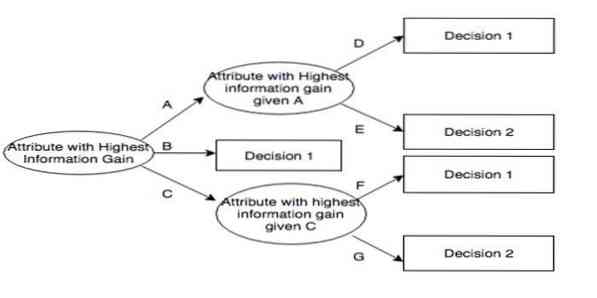
Итеративный дихотомизатор 3 (ID3) - это алгоритмическое правило обучения дерева решений, представленное Россом Куинланом, которое используется для предоставления дерева решений из набора данных. Это предшественник C4.5 и используется в областях машинного обучения и лингвистической коммуникации.
ID3 может переоснастить данные обучения. Это алгоритмическое правило сложнее использовать для непрерывных данных. Это не гарантирует оптимального решения.
14. Иерархическая кластеризация
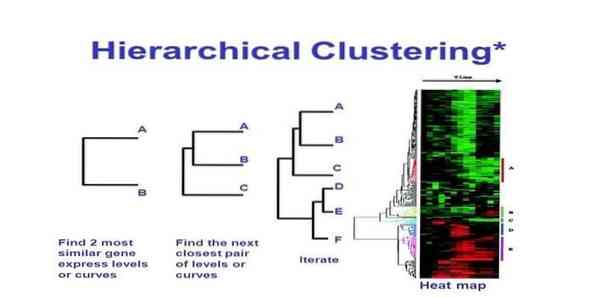
Иерархическая кластеризация - это способ кластерного анализа. В иерархической кластеризации создается дерево кластеров (дендрограмма) для иллюстрации данных. В иерархической кластеризации каждая группа (узел) связана с двумя или более группами-преемниками. Каждый узел в дереве кластера содержит похожие данные. Группа узлов на графе рядом с другими похожими узлами.
Алгоритм
Этот метод машинного обучения можно разделить на две модели - вверх дном или же низходящий:
Снизу вверх (иерархическая агломеративная кластеризация, HAC)
- В начале этой техники машинного обучения каждый документ рассматривается как единый кластер.
- В новом кластере объединены по два элемента за раз. Как объединение комбайнов включает в себя расчетную разницу между каждой включенной парой и, следовательно, альтернативными образцами. Для этого есть много вариантов. Некоторые из них:
а. Полная связь: Сходство самой дальней пары. Одно ограничение заключается в том, что выбросы могут вызвать слияние близких групп позже, чем это необходимо.
б. Одинарная связь: Сходство ближайшей пары. Это может вызвать преждевременное слияние, хотя эти группы совершенно разные.
c. Среднее по группе: сходство между группами.
d. Центроидное сходство: каждая итерация объединяет кластеры с наиболее похожей центральной точкой.
- Пока все элементы не объединятся в один кластер, процесс сопряжения продолжается.
Сверху вниз (разделяющая кластеризация)
- Данные начинаются с комбинированного кластера.
- Кластер делится на две отдельные части в зависимости от некоторой степени сходства.
- Кластеры снова и снова делятся на два, пока кластеры не будут содержать только одну точку данных.
15. Обратное распространение
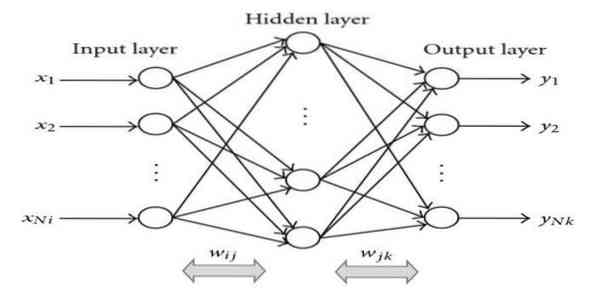
Обратное распространение - это алгоритм обучения с учителем. Этот алгоритм ML происходит из области искусственных нейронных сетей (ANN). Эта сеть представляет собой многоуровневую сеть прямого распространения. Этот метод направлен на создание заданной функции путем изменения внутренних весов входных сигналов для получения желаемого выходного сигнала. Его можно использовать для классификации и регрессии.

Алгоритм обратного распространения имеет некоторые преимущества, i.е., его легко реализовать. Математическая формула, используемая в алгоритме, может быть применена к любой сети. Время вычисления может быть уменьшено, если веса маленькие.
Алгоритм обратного распространения имеет некоторые недостатки, например, он может быть чувствителен к зашумленным данным и выбросам. Это полностью матричный подход. Фактическая производительность этого алгоритма полностью зависит от входных данных. Вывод может быть нечисловым.
16. AdaBoost
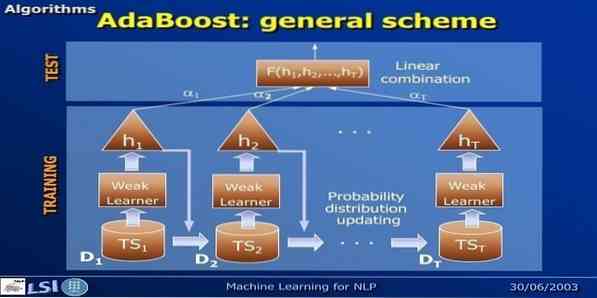
AdaBoost означает Adaptive Boosting, метод машинного обучения, представленный Йоавом Фройндом и Робертом Шапиром. Это мета-алгоритм, который можно интегрировать с другими алгоритмами обучения для повышения их производительности. Этот алгоритм быстр и прост в использовании. Хорошо работает с большими наборами данных.
17. Глубокое обучение
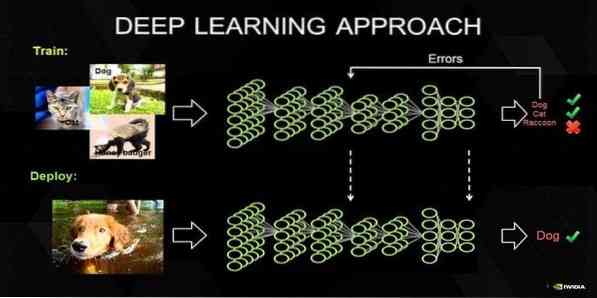
Глубокое обучение - это набор методов, вдохновленных механизмом человеческого мозга. Два основных направления глубокого обучения, я.е., Сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN) используются в классификации текста. Алгоритмы глубокого обучения, такие как Word2Vec или GloVe, также используются для получения высокорейтинговых векторных представлений слов и повышения точности классификаторов, которые обучаются с помощью традиционных алгоритмов машинного обучения.
Этот метод машинного обучения требует большого количества обучающей выборки вместо традиционных алгоритмов машинного обучения, i.е., минимум миллионы помеченных примеров. С другой стороны, традиционные методы машинного обучения достигают точного порога, когда добавление дополнительной обучающей выборки не улучшает их точность в целом. Классификаторы глубокого обучения показывают лучшие результаты с большим количеством данных.
18. Алгоритм повышения градиента

Повышение градиента - это метод машинного обучения, который используется для классификации и регрессии. Это один из самых эффективных способов разработки прогнозной модели. Алгоритм повышения градиента состоит из трех элементов:
- Функция потерь
- Слабый ученик
- Аддитивная модель
19. Сеть Хопфилда
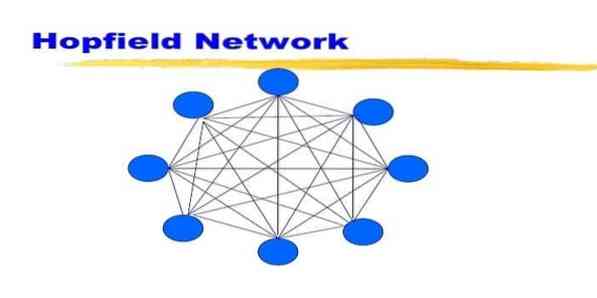
Сеть Хопфилда - это один из видов рекуррентной искусственной нейронной сети, созданный Джоном Хопфилдом в 1982 году. Эта сеть предназначена для хранения одного или нескольких шаблонов и вызова полных шаблонов на основе частичного ввода. В сети Хопфилда все узлы являются как входами, так и выходами и полностью взаимосвязаны.
20. C4.5

C4.5 - это дерево решений, изобретенное Россом Куинланом. Это обновленная версия ID3. Эта алгоритмическая программа включает несколько базовых случаев:
- Все образцы в списке относятся к одной категории. Он создает листовой узел для дерева решений, предлагая выбрать эту категорию.
- Он создает узел решения выше по дереву, используя ожидаемое значение класса.
- Он создает узел решения выше по дереву, используя ожидаемое значение.
Конечные мысли
Очень важно использовать правильный алгоритм, основанный на ваших данных и предметной области, для разработки эффективного проекта машинного обучения. Кроме того, важно понимать критическую разницу между каждым алгоритмом машинного обучения, когда я выбираю, какой из них.'Как и в случае с машинным обучением, машина или устройство обучались с помощью алгоритма обучения. Я твердо верю, что эта статья поможет вам разобраться в алгоритме. Если у вас есть предложения или вопросы, не стесняйтесь спрашивать. Продолжай читать.


