
Практически все начинающие специалисты по обработке данных и разработчики машинного обучения затрудняются выбрать язык программирования. Они всегда спрашивают, какой язык программирования лучше всего подходит для их проекта по машинному обучению и науке о данных. Либо мы выберем python, R или MatLab. Что ж, выбор языка программирования зависит от предпочтений разработчиков и системных требований. Среди других языков программирования R - один из самых потенциальных и великолепных языков программирования, в котором есть несколько пакетов машинного обучения R для проектов машинного обучения, искусственного интеллекта и анализа данных.
Как следствие, с помощью этих пакетов машинного обучения R можно легко и эффективно разработать свой проект. Согласно опросу Kaggle, R - один из самых популярных языков машинного обучения с открытым исходным кодом.
Лучшие пакеты машинного обучения R
R - это язык с открытым исходным кодом, поэтому люди могут вносить свой вклад из любой точки мира. Вы можете использовать черный ящик в своем коде, который написан кем-то другим. В R этот черный ящик называется пакетом. Пакет - это не что иное, как заранее написанный код, который может многократно использоваться кем угодно. Ниже мы представляем 20 лучших пакетов машинного обучения R.
1. CARET
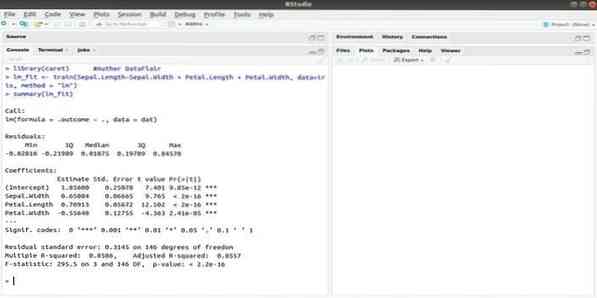 Пакет CARET относится к классификационному и регрессионному обучению. Задача этого пакета CARET - интегрировать обучение и прогнозирование модели. Это один из лучших пакетов R для машинного обучения и обработки данных.
Пакет CARET относится к классификационному и регрессионному обучению. Задача этого пакета CARET - интегрировать обучение и прогнозирование модели. Это один из лучших пакетов R для машинного обучения и обработки данных.
Параметры можно искать, интегрируя несколько функций для расчета общей производительности данной модели, используя метод поиска по сетке этого пакета. После успешного прохождения всех испытаний поиск по сетке наконец находит лучшие комбинации.
После установки этого пакета разработчик может запустить names (getModelInfo ()), чтобы увидеть 217 возможных функций, которые можно запустить только с помощью одной функции. Для построения прогнозной модели в пакете CARET используется функция train (). Синтаксис этой функции:
поезд (формула, данные, метод)
Документация
2. случайныйЛес
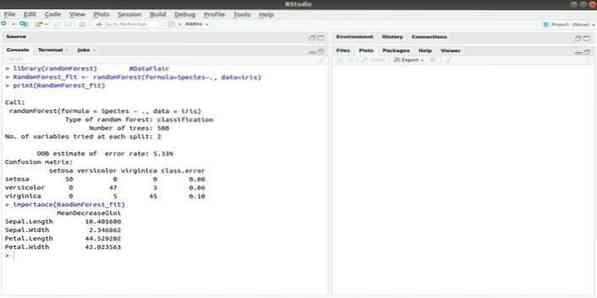
RandomForest - один из самых популярных пакетов R для машинного обучения. Этот пакет машинного обучения R можно использовать для решения задач регрессии и классификации. Кроме того, его можно использовать для обучения отсутствующих значений и выбросов.
Этот пакет машинного обучения с R обычно используется для генерации нескольких деревьев решений. В основном это случайные выборки. Затем наблюдения заносятся в дерево решений. Наконец, общий результат, полученный из дерева решений, является конечным результатом. Синтаксис этой функции:
randomForest (формула =, данные =)
Документация
3. e1071
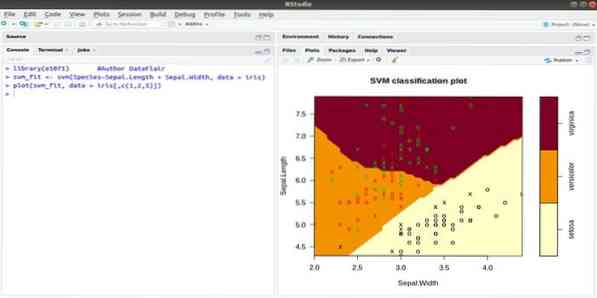
Этот e1071 - один из наиболее широко используемых пакетов R для машинного обучения. Используя этот пакет, разработчик может реализовать поддержку векторных машин (SVM), вычисление кратчайшего пути, групповую кластеризацию, наивный байесовский классификатор, кратковременное преобразование Фурье, нечеткую кластеризацию и т. Д.
Например, для данных IRIS синтаксис SVM:
svm (Вид ~ Чашелистник.Длина + чашелистик.Ширина, данные = диафрагма)
Документация
4. Rpart
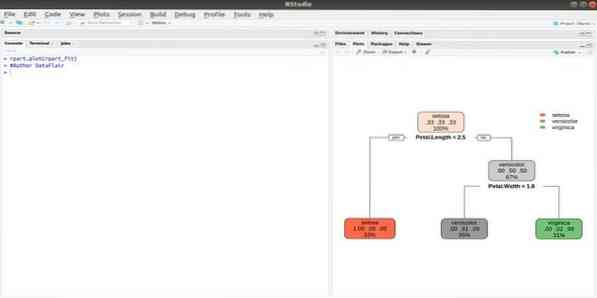
Rpart означает рекурсивное разделение и регрессионное обучение. Этот пакет R для машинного обучения может выполнять обе задачи: классификацию и регрессию. Действует с использованием двухступенчатого шага. Выходная модель - двоичное дерево. Функция plot () используется для построения выходного результата. Кроме того, существует альтернативная функция prp (), которая более гибкая и мощная, чем базовая функция plot ().
Функция rpart () используется для установления связи между независимыми и зависимыми переменными. Синтаксис:
rpart (формула, данные =, метод =, элемент управления =)
где формула - это комбинация независимых и зависимых переменных, данные - это имя набора данных, метод - это цель, а контроль - это требования вашей системы.
Документация
5. KernLab
Если вы хотите разработать свой проект на основе алгоритмов машинного обучения на основе ядра, вы можете использовать этот пакет R для машинного обучения. Этот пакет используется для SVM, анализа функций ядра, алгоритма ранжирования, примитивов скалярного произведения, гауссовского процесса и многого другого. KernLab широко используется для реализации SVM.
Доступны различные функции ядра. Здесь упоминаются некоторые функции ядра: polydot (функция ядра полинома), tanhdot (функция ядра гиперболического тангенса), laplacedot (функция ядра лапласа) и т. Д. Эти функции используются для решения задач распознавания образов. Но пользователи могут использовать свои функции ядра вместо предопределенных функций ядра.
Документация
6. nnet
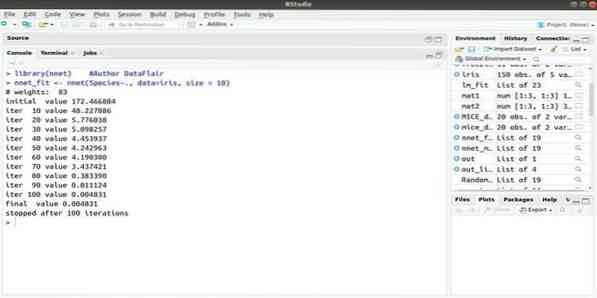 Если вы хотите разработать приложение для машинного обучения с использованием искусственной нейронной сети (ИНС), этот пакет nnet может вам помочь. Это один из самых популярных и простых в реализации пакетов нейронных сетей. Но это ограничение в том, что это один слой узлов.
Если вы хотите разработать приложение для машинного обучения с использованием искусственной нейронной сети (ИНС), этот пакет nnet может вам помочь. Это один из самых популярных и простых в реализации пакетов нейронных сетей. Но это ограничение в том, что это один слой узлов.
Синтаксис этого пакета:
nnet (формула, данные, размер)
Документация
7. dplyr
Один из наиболее широко используемых пакетов R для науки о данных. Кроме того, он предоставляет несколько простых в использовании, быстрых и последовательных функций для управления данными. Хэдли Уикхэм пишет этот пакет программирования r для науки о данных. Этот пакет состоит из набора глаголов i.е., mutate (), select (), filter (), summarize () и организовать ().
Чтобы установить этот пакет, нужно написать этот код:
установить.пакеты («dplyr»)
И чтобы загрузить этот пакет, вы должны написать такой синтаксис:
библиотека (dplyr)
Документация
8. ggplot2
Еще один из самых элегантных и эстетичных пакетов R для графических фреймворков для науки о данных - ggplot2. Это система создания графики на основе грамматики графики. Синтаксис установки этого пакета для обработки данных:
установить.пакеты («ggplot2»)
Документация
9. Wordcloud

Когда одно изображение состоит из тысяч слов, оно называется Wordcloud. По сути, это визуализация текстовых данных. Этот пакет машинного обучения с использованием R используется для создания представления слов, и разработчик может настроить Wordcloud в соответствии со своими предпочтениями, например, расположить слова случайным образом или слова с одинаковой частотой вместе или часто встречающиеся слова в центре и т. Д.
В языке машинного обучения R доступны две библиотеки для создания wordcloud: Wordcloud и Worldcloud2. Здесь мы покажем синтаксис WordCloud2. Для установки WordCloud2 необходимо написать:
1. требуется (инструменты разработчика)
2. install_github («lchiffon / wordcloud2»)
Или вы можете использовать его напрямую:
библиотека (wordcloud2)
Документация
10. тидир
Еще один широко используемый пакет r для науки о данных - tidyr. Цель этого r-программирования для науки о данных - привести данные в порядок. В tidy переменная помещается в столбец, наблюдение помещается в строку, а значение находится в ячейке. Этот пакет описывает стандартный способ сортировки данных.
Для установки можно использовать этот фрагмент кода:
установить.пакеты («тидыр»)
Код для загрузки:
библиотека (тидыр)
Документация
11. блестящий
Пакет R, Shiny, является одним из фреймворков веб-приложений для анализа данных. Это помогает легко создавать веб-приложения из R. Либо разработчик может установить программное обеспечение в каждой клиентской системе, либо разместить веб-страницу. Кроме того, разработчик может создавать информационные панели или встраивать их в документы R Markdown.
Кроме того, приложения Shiny могут быть расширены с помощью различных языков сценариев, таких как виджеты html, темы CSS и действия JavaScript. Одним словом, можно сказать, что этот пакет представляет собой сочетание вычислительной мощности R с интерактивностью современной сети.
Документация
12. тм
Излишне говорить, что интеллектуальный анализ текста - это новое приложение машинного обучения в наши дни. Этот пакет машинного обучения R предоставляет основу для решения задач интеллектуального анализа текста. В приложении для интеллектуального анализа текста я.е., анализ настроений или классификация новостей, разработчик выполняет различные утомительные работы, такие как удаление нежелательных и неактуальных слов, удаление знаков препинания, удаление стоп-слов и многое другое.
Пакет tm содержит несколько гибких функций, облегчающих вашу работу, например removeNumbers (): для удаления чисел из заданного текстового документа, weightTfIdf (): для частоты термина и обратной частоты документа, tm_reduce (): для объединения преобразований, removePunctuation () для удалить знаки препинания из данного текстового документа и многое другое.
Документация
13. Пакет MICE
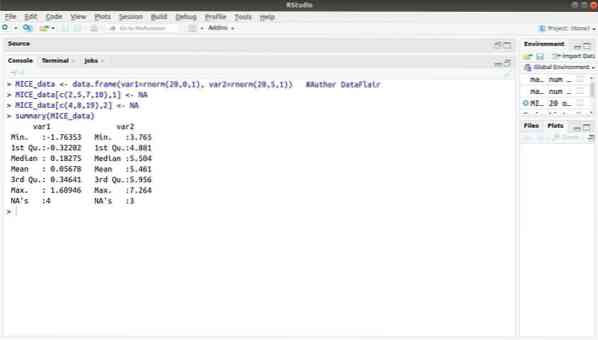
Пакет машинного обучения с R, MICE относится к многомерному вменению через связанные последовательности. Почти все время разработчик проекта сталкивается с общей проблемой с набором данных машинного обучения - отсутствующим значением. Этот пакет можно использовать для вменения недостающих значений с помощью нескольких методов.
Этот пакет содержит несколько функций, таких как проверка шаблонов отсутствующих данных, диагностика качества вмененных значений, анализ завершенных наборов данных, хранение и экспорт вмененных данных в различных форматах и многое другое.
Документация
14. граф
Пакет сетевого анализа igraph - один из мощных пакетов R для науки о данных. Это набор мощных, эффективных, простых в использовании и портативных инструментов сетевого анализа. Кроме того, этот пакет имеет открытый исходный код и бесплатный. Кроме того, igraphn можно программировать на Python, C / C ++ и Mathematica.
В этом пакете есть несколько функций для генерации случайных и регулярных графиков, визуализации графика и т. Д. Кроме того, вы можете работать с вашим большим графом, используя этот пакет R. Для использования этого пакета есть некоторые требования: для Linux необходимы компиляторы C и C ++.
Установка этого пакета программирования R для науки о данных:
установить.пакеты («igraph»)
Для загрузки этого пакета необходимо написать:
библиотека (igraph)
Документация
15. РПЦЗ
Пакет R для науки о данных, ROCR, используется для визуализации производительности оценочных классификаторов. Этот пакет гибкий и простой в использовании. Требуются только три команды и значения по умолчанию для дополнительных параметров. Этот пакет используется для разработки 2D-кривых производительности с параметрами отсечки. В этом пакете есть несколько функций, таких как prediction (), которые используются для создания объектов прогнозирования, performance (), используемые для создания объектов производительности, и т. Д.
Документация
16. DataExplorer
Пакет DataExplorer - один из самых простых в использовании пакетов R для науки о данных. Среди множества задач науки о данных исследовательский анализ данных (EDA) является одной из них. При исследовательском анализе данных аналитик данных должен уделять больше внимания данным. Проверять или обрабатывать данные вручную или использовать плохое кодирование - непростая задача. Нужна автоматизация анализа данных.
Этот пакет R для науки о данных обеспечивает автоматизацию исследования данных. Этот пакет используется для сканирования и анализа каждой переменной и их визуализации. Это полезно, когда набор данных большой. Таким образом, анализ данных может эффективно и без усилий извлекать скрытые знания из данных.
Пакет можно установить из CRAN напрямую, используя приведенный ниже код:
установить.пакеты («DataExplorer»)
Чтобы загрузить этот пакет R, вы должны написать:
библиотека (DataExplorer)
Документация
17. млр
Один из самых невероятных пакетов машинного обучения R - это пакет mlr. Этот пакет является шифрованием нескольких задач машинного обучения. Это означает, что вы можете выполнять несколько задач, используя только один пакет, и вам не нужно использовать три пакета для трех разных задач.
Пакет mlr - это интерфейс для множества методов классификации и регрессии. Эти методы включают в себя машиночитаемые описания параметров, кластеризацию, общую повторную выборку, фильтрацию, извлечение признаков и многое другое. Также можно выполнять параллельные операции.
Для установки вы должны использовать следующий код:
установить.пакеты («млр»)
Чтобы загрузить этот пакет:
библиотека (млр)
Документация
18. Arules
Пакет arules (правила ассоциации майнинга и частые наборы элементов) является широко используемым пакетом машинного обучения R. Используя этот пакет, можно выполнить несколько операций. Операции представляют собой представление и анализ транзакций данных и шаблонов, а также манипулирование данными. Также доступны реализации C алгоритмов ассоциативного анализа Apriori и Eclat.
Документация
19. mboost
Еще один пакет машинного обучения R для науки о данных - mboost. Этот пакет повышения на основе моделей имеет функциональный алгоритм градиентного спуска для оптимизации общих функций риска с использованием деревьев регрессии или покомпонентных оценок наименьших квадратов. Кроме того, он предоставляет модель взаимодействия с потенциально многомерными данными.
Документация
20. вечеринка
Еще один пакет в машинном обучении с R - вечеринка. Этот вычислительный набор инструментов используется для рекурсивного разбиения. Основная функция или ядро этого пакета машинного обучения - ctree (). Это широко используемая функция, которая сокращает время обучения и сокращает систематические ошибки.
Синтаксис ctree ():
ctree (формула, данные)
Документация
Конечные мысли
R - такой выдающийся язык программирования, который использует статистические методы и графики для исследования данных. Излишне говорить, что у этого языка есть несколько пакетов машинного обучения R, невероятный инструмент RStudio и простой для понимания синтаксис для разработки сложных проектов машинного обучения. В пакете R ml есть несколько значений по умолчанию. Прежде чем применять его в своей программе, вы должны подробно узнать о различных вариантах. Используя эти пакеты машинного обучения, любой может построить эффективную модель машинного обучения или науки о данных. Наконец, R - это язык с открытым исходным кодом, и его пакеты постоянно расширяются.
Если у вас есть предложения или вопросы, оставьте комментарий в нашем разделе комментариев. Вы также можете поделиться этой статьей со своими друзьями и семьей в социальных сетях.


